Flux is a refinement type checker plugin for Rust that lets you specify a range of correctness properties and have them be verified at compile time.
Flux works by extending Rust's types with refinements: logical assertions describing additional correctness requirements that are checked during compilation, thereby eliminating various classes of run-time problems.
You can try it on the online playground.
Better still, read the interactive tutorial, to learn how you can use Flux on your Rust code.
Installing and Running Flux
You can install and then run Flux either on a single file or on an entire crate.
Quick Install (Linux / macOS)
curl -fsSL https://raw.githubusercontent.com/flux-rs/flux/main/install.sh | bash
Requirements
-
Rustup is required because Flux needs access to the source code of the Rust compiler, which we grab from rustup.
-
Nightly binary builds are avilable on GitHub Releases. If there is no binary available for your platform, you will need to build it from source.
-
z3 4.15 or later
You can download a binary for your platform from Z3 GitHub Releases. We recommend downloading the latest version, but older version should also work.
Note:
Make sure that the liquid-fixpoint and z3 binaries are in your $PATH.
Install
The only way to use Flux is to build it from source.
First you need to clone the repository
git clone https://github.com/flux-rs/flux
cd flux
To build the source you need a nightly version of rustc.
We pin the version using a toolchain file (more info here).
If you are using rustup, no special action is needed as it should install the correct rustc version and components based on the information on that file.
Next, run the following to build and install flux binaries
cargo xtask install
This will install two binaries flux and cargo-flux in your cargo home. These two binaries should be used
respectively to run Flux on either a single file or on a project using cargo. The installation process will
also copy some files to $HOME/.flux.
Running on a package: cargo-flux
The most common way to use Flux is to run it on a Cargo package.
This allows you to check an entire crate in one command, cargo flux.
Step 1: Install Flux
Install Flux as described above.
Step 2: Enable Flux for the Package
By default, Flux won't verify a package unless it's explicitly enabled in the manifest.
To do so add the following to Cargo.toml:
[package.metadata.flux]
enabled = true
Now you can run cargo flux to check the package.
Step 3: Enable Refinement Attributes
In step 2, you will likely get some refinement errors, and to remove
those you will need to add some refinement annotations to your code.
To do so, add the following to your Cargo.toml, which
adds the procedural macros Flux uses to your project
[dependencies]
flux-rs = { git = "https://github.com/flux-rs/flux.git" }
Then, import attributes from flux_rs and add the appropriate refinement annotations.
#![allow(unused)] fn main() { use flux_rs::attrs::*; #[spec(fn(x: i32) -> i32{v: x < v})] fn inc(x: i32) -> i32 { x - 1 } }
Running on a File: flux
You can use flux as you would use rustc.
For example, the following command checks the file test.rs.
flux path/to/test.rs
The flux binary accepts the same flags as rustc.
You could for example check a file as a library
instead of a binary like so
flux --crate-type=lib path/to/test.rs
Refinement Annotations on a File
When running flux on a file with flux path/to/test.rs, refinement annotations should be prefixed with flux::.
For example, the refinement below will only work when running flux which is intended for use on a single file.
#![allow(unused)] fn main() { #[flux::spec(fn(x: i32) -> i32{v: x < v})] fn inc(x: i32) -> i32 { x - 1 } }
A tiny example
The following example declares a function inc
that returns an integer greater than the input.
We use the nightly feature register_tool
to register the flux tool in order to
add refinement annotations to functions.
#![allow(unused)] fn main() { #[flux::spec(fn(x: i32) -> i32{v: x < v})] pub fn inc(x: i32) -> i32 { x - 1 } }
You can save the above snippet in say test0.rs and then run
flux --crate-type=lib path/to/test0.rs
you should see in your output
error[FLUX]: postcondition might not hold
--> test0.rs:3:5
|
3 | x - 1
| ^^^^^
as indeed x - 1 is not greater than x as required by the output refinement i32{v: x < v}.
If you fix the error by replacing x - 1 with x + 1, you should get no errors
in the output (the output may be empty, but in this case no output is a good
thing).
Read these chapters to learn more about what you specify and verify with flux.
A note about the flux-driver binary
The flux-driver binary is a rustc
driver
(similar to how clippy works) meaning it uses rustc as a library to "drive"
compilation performing additional analysis along the way. Running the binary
requires dynamically linking a correct version of librustc. Thus, to avoid the
hassle you should never execute it directly. Instead, use flux or cargo-flux.
Editor Support
This section assumes you have installed cargo-flux.
Rust-Analyzer in VSCode
Add this to the workspace settings i.e. .vscode/settings.json
{
"rust-analyzer.check.overrideCommand": [
"cargo",
"flux",
"--workspace",
"--message-format=json-diagnostic-rendered-ansi"
]
}
Note: Make sure to edit the paths in the above snippet to point to the correct locations on your machine.
Configuration
Flux Flags
The flux binary accepts configuration flags in the format -Fname=value. For boolean flags, the
value can be one of y, yes, on, true, n, no, off, false. Alternatively, the value
can be omitted which will default to true. For example, to set the solver to cvc5 and enable
qualifier scraping:
flux -Fsolver=cvc5 -Fscrape-quals path/to/file.rs
For all available flags, see https://flux-rs.github.io/flux/doc/flux_config/flags/struct.Flags.html
Cargo Projects
When working with a Cargo project, some of the flags can be configured in the
[package.metadata.flux] table in Cargo.toml. For example, to enable query caching and set
cvc5 as the solver:
# Cargo.toml
[package.metadata.flux]
enabled = true
cache = true
solver = "cvc5"
Additionally, cargo flux searches for a configuration file called flux.toml with the same format
as the metadata table. The content of flux.toml takes precedence and it's merged with the
content of the metadata table. Note that the content of flux.toml will override the metadata
for all crates, including dependencies. This behavior is likely to change in the future as we figure
out what configurations make sense to have per package and which should only affect the current execution
of cargo flux.
You can see the format of the metadata in https://flux-rs.github.io/flux/doc/flux_bin/struct.FluxMetadata.html.
FLUXFLAGS Environment Variable
When running cargo flux, flags defined in FLUXFLAGS will be passed to all flux invocations,
for example, to print timing information for all crates checked by Flux:
FLUXFLAGS="-Ftimings" cargo flux
Verbose Flag
One particularly useful flag is
FLUXFLAGS="-Fflux-verbose" cargo flux
This will make flux print out a log of what it is upto, e.g. the name of the last function checked. This is helpful, e.g. if flux ICEs (hits an internal error), so you can see which function's code caused the issue, so you might mark it as trusted, so flux can skip checking its body, and hence, live to fight another day...
About Flux
Team
Flux is being developed by
Code
Flux is open-source and available here
Publications
- Lehmann, Nico, Adam T. Geller, Niki Vazou, and Ranjit Jhala. "Flux: Liquid types for rust." PLDI (2023)
- Lehmann, Nico, Cole Kurashige, Nikhil Akiti, Niroop Krishnakumar, and Ranjit Jhala. "Generic Refinement Types." POPL (2025)
Talks
Thanks
This work was supported by the National Science Foundation, European Research Council, and by generous gifts from Microsoft Research.
Limitations
This is a prototype! Use at your own risk. Everything could break and it will break.
Refining Types
Types bring order to code. For example, if a variable i:usize
then we know i is a number that can be used to index a vector.
Similarly, if v: Vec<&str> then we can be sure that v is a
collection of strings which may be indexed but of course,
not used as an index. However, by itself usize doesn't
tell us how big or small the number and hence the programmer
must still rely on their own wits, a lot of tests, and a dash
of optimism, to ensure that all the different bits fit properly
at run-time.
Refinements are a promising new way to extend type checkers with logical constraints that specify additional correctness requirements that can be verified by the compiler, thereby entirely eliminating various classes of run-time problems.
To begin, let's see how flux lets you refine basic or primitive
types like i32 or usize or bool with logical constraints that
can be checked at compile time.
Indexed Types
The simplest kind of refinement type in flux is a type that is indexed by a logical value. For example
| Type | Meaning |
|---|---|
i32[10] | The (singleton) set of i32 values equal to 10 |
bool[true] | The (singleton) set of bool values equal to true |
Flux Specifications
First off, we need to add some incantations that pull in the mechanisms for writing flux specifications as Rust attributes.
#![allow(unused)] extern crate flux_rs; use flux_rs::attrs::*;
Post-Conditions
We can already start using these indexed types to start writing (and checking)
code. For example, we can write the following specification which says that
the value returned by mk_ten must in fact be 10
#[spec(fn() -> i32[10])] pub fn mk_ten() -> i32 { 5 + 4 }
Push Play Push the "run" button in the pane above. You will see a red squiggle that and when you hover over the squiggle you will see an error message
error[...]: refinement type error
|
7 | 5 + 4
| ^^^^^ a postcondition cannot be proved
which says that that the postcondition might not hold which means
that the output produced by mk_ten may not in fact be an i32[10]
as indeed, in this case, the result is 9! You can eliminate the error
by editing the body to 5 + 4 + 1 or 5 + 5 or just 10.
Pre-Conditions
You can use an index to restrict the inputs that a function expects to be called with.
#[spec(fn (b:bool[true]))] pub fn assert(b:bool) { if !b { panic!("assertion failed") } }
The specification for assert says you can only call
it with true as the input. So if you write
fn test(){ assert(2 + 2 == 4); assert(2 + 2 == 5); // fails to type check }
then flux will complain that
error[FLUX]: precondition might not hold
|
12 | assert(2 + 2 == 5); // fails to type check
| ^^^^^^^^^^^^^^^^^^
meaning at the second call to assert the input may not
be true, as of course, in this case, it is not!
Can you edit the code of test to fix the error?
Index Parameters and Expressions
Its not terribly exciting to only talk about fixed values
like 10 or true. To be more useful, flux lets you index
types by refinement parameters. For example, you can write
#[spec(fn(n:i32) -> bool[0 < n])] pub fn is_pos(n: i32) -> bool { if 0 < n { true } else { false } }
Here, the type says that is_pos
- takes as input some
i32indexed byn - returns as output the
boolindexed by0 < n
That is, is_pos returns true exactly when 0 < n.
We might use this function to check that:
pub fn test_pos(n: i32) { let m = if is_pos(n) { n - 1 } else { 0 }; assert(0 <= m); }
Existential Types
Often we don't care about the exact value of a thing -- but just
care about some properties that it may have. For example, we don't
care that an i32 is equal to 5 or 10 or n but that it is
non-negative.
| Type | Meaning |
|---|---|
i32{v: 0 < v} | The set of i32 values that are positive |
i32{v: n <= v} | The set of i32 values greater than or equal to n |
Flux allows such specifications by pairing plain Rust types with assertions 1 that constrain the value.
Existential Output Types
For example, we can rewrite mk_10 with the output type
i32{v:0<v} that specifies a weaker property:
the value returned by mk_ten_pos is positive.
#[spec(fn() -> i32{v: 0 < v})] pub fn mk_ten_pos() -> i32 { 5 + 5 }
Example: absolute value
Similarly, you might specify that a function that computes the absolute
value of an i32 with a type which says the result is non-negative and
exceeds the input n.
#[spec(fn (n:i32) -> i32{v:0<=v && n<=v})] pub fn abs(n: i32) -> i32 { if 0 <= n { n } else { 0 - n } }
Combining Indexes and Constraints
Sometimes, we want to combine indexes and constraints in a specification.
For example, suppose we have some code that manipulates
scores which are required to be between 0 and 100.
Now, suppose we want to write a function that adds k
points to a score s. We want to specify that
- The inputs
sandkmust be non-negative, - the inputs
s + k <= 100, and - The output equals
s + k
#[spec(fn ({usize[@s] | s + k <= 100}, k:usize) -> usize[s + k])] fn add_points(s: usize, k: usize) -> usize { s + k } fn test_add_points() { assert(add_points(20, 30) == 50); assert(add_points(90, 30) == 120); // fails to type check }
Note that we use the @s to index the value of the s parameter,
so that we can
- constrain the inputs to
s + k <= 100, and - refine the value of the output to be exactly
usize[s + k].
EXERCISE Why does flux reject the second call to add_points?
Example: factorial
As a last example, you might write a function to compute the factorial of n
#[spec(fn (n:i32) -> i32{v:1<=v && n<=v})] pub fn factorial(n: i32) -> i32 { let mut i = 0; let mut res = 1; while i < n { i += 1; res = res * i; } res }
Here the specification says the input must be non-negative, and the
output is at least as large as the input. Note, that unlike the previous
examples, here we're actually changing the values of i and res.
Summary
In this post, we saw how Flux lets you
-
decorate basic Rust types like
i32andboolwith indices and constraints that let you respectively refine the sets of values that inhabit that type, and -
specify contracts on functions that state pre-conditions on the sets of legal inputs that they accept, and post-conditions that describe the outputs that they produce.
The whole point of Rust, of course, is to allow for efficient imperative sharing and updates, without sacrificing thread- or memory-safety. Next time, we'll see how Flux melds refinements and Rust's ownership to make refinements happily coexist with imperative code.
-
These are not arbitrary Rust expressions but a subset of expressions from logics that can be efficiently decided by SMT Solvers ↩
Ownership in Flux
Previously we saw how to refine basic Rust
types like i32 and bool with indices and constraints to
constrain the set of values described by those types. For instance, we
wrote the function assert function which can only be called with true
#[flux_rs::spec(fn (bool[true]))] fn assert(b: bool) { if !b { panic!("assertion failed"); } } fn test_assert() { assert(2 + 2 == 4); assert(2 + 2 == 5); // fails to type check }
The whole point of Rust, of course, is to allow for efficient imperative sharing and updates, via the clever type system that keeps an eye on the ownership of resources to make sure that aliasing and mutation cannot happen at the same time.
Next, lets see how Flux melds refinements and Rust's ownership mechanisms to make refinements pleasant in the imperative setting.
Exclusive Ownership
Rust's most basic form of sharing is exclusive ownership,
in which exactly one variable in a function has the right to
mutate a memory location. When a location is exclusively
owned, we can be sure that there are no other references
to it. Consequently, flux can update the type to precisely
track the value whenever the location is changed.
For example, consider the program
#[flux_rs::spec(fn () -> i32[3])] pub fn mk_three() -> i32 { let mut r = 0; // r: i32[0] r += 1; assert(r == 1); // r: i32[1] r += 1; assert(r == 2); // r: i32[2] r += 1; assert(r == 3); // r: i32[3] r }
The variable r has different types at each point inside mk_three.
It starts off as i32[0]. The first increment changes it to i32[1],
then i32[2] and finally, the returned type i32[3].
Exclusive Ownership and Loops
This exclusive ownership mechanism is at work in the factorial example
we signed off with previously
#[flux_rs::spec(fn (n:i32{0 <= n}) -> i32{v:n <= v})] pub fn factorial(n: i32) -> i32 { let mut i = 0; // i: i32[0] let mut r = 1; // r: i32[1] while i < n { // i: i32{v:0 <= v <= n} // r: i32{v:1 <= v && i <= v} i += 1; r = r * i; } r }
In the above code, i and r start off at 0 and 1 but then
flux infers (a story for another day) that inside the while-loop1
ihas typei32{v:0<=v && v < n}rhas typei32{v:1<=v && i <= v}
and hence, upon exit since i == n we get that the result is at least n.
Borrowing: Shared References
Exclusive ownership suffices for simple local updates
like in factorial. However, for more complex data,
functions must temporarily relinquish ownership to
allow other functions to mutate the data.
Rust cleverly allows this via the notion of borrowing using two kinds of references that give callee functions temporary access to memory location.
The simplest kind of references are &T
which denote read-only access to a value
of type T. For example, we might write abs to take
a shared reference to an i32
#[flux_rs::spec(fn (p: &i32[@n]) -> i32{v:0<=v && n<=v})] pub fn abs(p: &i32) -> i32 { let n = *p; if 0 <= n { n } else { 0 - n } }
Notice that the input type has changed. Now, the function
- accepts
p, a reference to ani32whose value isnas denoted by@n - returns an
i32that is non-negative and larger thann
The @ marks the n as a refinement parameter whose value
is automatically computed by flux during type checking.
Calling abs with a reference
So, for example, Flux can check the below code by automatically
determining that the refinement parameter at the call-site is 10.
pub fn test_abs() { let z = 10; assert(0 <= abs(&z)); assert(10 <= abs(&z)) }
Refinement Parameters
As an aside, we have secretly been using refinement parameters
like @n all along. For example, Flux automatically desugars
the signature fn(n:i32{0 <= n} -> ... that we wrote for factorial into
fn ({i32[@n] : 0 <= n}) -> i32{v:n <= v}
where @n is a refinement parameter that is implicitly determined
from the rust parameter n:i32. However, explicit parameters are
essential to name the value of what a reference points to.
In abs the rust parameter p names the reference but the
@n names the (input) value and lets us use it to provide
more information about the output of abs.
EXERCISE Flux is modular in that the
only information it knows about the
implementation of abs is the signature.
For example, suppose we change the output type
of abs to i32{v:0<=v}, that is, we remove the
n <= v conjunct. Can you predict which assert
will be rejected by flux?
Borrowing: Mutable References
References of type &mut T denote mutable references that can be
used to (read and) write or update the contents of a T value.
Crucially, Rust ensures that while there may be multiple read-only (shared)
references to a location, there is at most one active writeable (mutable)
reference at any point in time.
Flux exploits the semantics of &mut T to treat T as an invariant
of the underlying data. As an example, consider the following function
that decrements the value of a mutable reference while ensuring the
data is non-negative:
#[flux_rs::spec(fn(p: &mut i32{v:0 <= v}))] pub fn decr(p: &mut i32) { *p = *p - 1; }
Flux complains that
error[FLUX]: assignment might be unsafe
|
13 | *p = *p - 1;
| ^^^^^^^^^^^
as in fact, we may be writing a negative value into *p
for example, if the old value was zero. We can fix this
code by guarding the update with a test that ensures the
original contents are in fact non-zero
EXERCISE Can you modify the code for decr so that flux verifies it?
Aliased References
Flux uses Rust's borrowing rules to track invariants even when there may be aliasing. As an example, consider the function
#[flux_rs::spec(fn (bool) -> i32{v:0 <= v})] fn test_alias(z: bool) -> i32 { let mut x = 1; // x: i32[1] let mut y = 2; // y: i32[2] let r = if z { &mut x } else { &mut y }; // r: &mut i32{v:0 <= v} decr(r); *r }
The reference r could point to either x or y depending
on the (unknown) value of the boolean z. Nevertheless, Flux
determines that both references &mut x and &mut y point
to values of the more general type i32{v:0<=v} and hence,
infers r : &mut i32{v:0<=v} which allows us it to then call
decr with the reference and guarantee the result (after decr)
is still non-negative.
Invariants are not enough!
In many situations, we want to lend a value to another function
that actually changes the value's (refinement) type upon exit.
For example, consider the following function to increment
a reference to a non-negative i32
#[flux_rs::spec(fn (p: &mut i32{v:0 <= v}))] fn incr_inv(p: &mut i32) { *p += 1 } fn test_incr_inv() { let mut z = 10; incr_inv(&mut z); assert(z == 11); }
The only information that flux has about incr what
it says in its spec, namely, that p remains non-negative.
Flux is blissfully unaware that incr increments
the value of p, and it cannot prove that after the
call, z == 11 and hence, complains that assert
may fail even though it will obviously succeed!
Borrowing: Updatable References
To verify test_incr we need a signature for incr that says
that its output is indeed one greater2 than its input.
Flux extends Rust &mut T with the notion of updatable references
which additionally specify how the type is changed when
the function exits3, using an ensures clause that specifies
the modified type of the reference.
#[flux_rs::spec(fn(p: &mut i32[@n]) ensures p:i32[n+1])] fn incr(p: &mut i32) { *p += 1 }
The Flux signature refines the plain Rust one to specify that
pis a strong reference to ani32,- the input type of
*pisi32[n], and - the output type of
*pisi32[n+1].
With this specification, Flux merrily checks test_incr, by
determining that the refinement parameter @n is 10 and
hence, that upon return x: i32[11].
fn test_incr() { let mut z = 10; incr(&mut z); assert(z == 11); }
Summary
To sum up, Flux exploits Rust's ownership mechanisms
to track properties of shared (&T) and mutable
(&mut T) references, and additionally uses (ensures)
clauses to specify when the type itself is changed by a call.
-
For those familiar with the term, these types are loop invariants ↩
-
Setting aside the issue of overflows for now ↩
-
Thereby allowing so-called strong updates in the type specifications ↩
Refining Structs
Previously, we saw how to slap refinements on existing built-in or primitive Rust types. For example,
i32[10]specifies thei32that is exactly equal to10andi32{v: 0 <= v && v < 10}specifies ani32between0and10.
Next, lets see how to attach refinements to user-defined types, so we can precisely define the set of legal values of those types.
Positive Integers
Lets start with an example posted on the flux gitHub:
how do you create a Positivei32? I can think of two ways:
struct Positivei32 { val: i32, }and structPositivei32(i32);but I do not know how to apply the refinements for them. I want it to be an invariant that the i32 value is >= 0. How would I do this?
With flux, you can define the Positivei32 type as follows:
#[refined_by(n: int)] #[invariant(n > 0)] struct Positivei32 { #[field(i32[n])] val: i32 }
In addition to defining the plain Rust type Positivei32,
the flux refinements say three distinct things.
- The
refined_by(n: int)tells flux to refine eachPositivei32with a specialint-sorted index namedn, - the
invariant(n > 0)says that the indexnis always positive, and, - the
fieldattribute onvalsays that the type of the fieldvalis ani32[n]i.e. is ani32whose exact value isn.
Creating Positive Integers
Now, you would create a Positivei32 pretty much as you might in Rust:
#[spec(fn() -> Positivei32)] fn mk_positive_1() -> Positivei32 { Positivei32 { val: 1 } }
and flux will prevent you from creating an illegal Positivei32, like
#[spec(fn() -> Positivei32)] fn mk_positive_0() -> Positivei32 { Positivei32 { val: 0 } }
A Constructor
EXERCISE Consider the following new constructor for Positivei32. Why does flux reject it?
Can you figure out how to fix the spec for the constructor so flux will be appeased?
impl Positivei32 { pub fn new(val: i32) -> Self { Positivei32 { val } } }
A "Smart" Constructor
EXERCISE Here is a different, constructor that should work
for any input n but which may return None if the input is
invalid. Can you fix the code so that flux accepts new_opt?
impl Positivei32 { pub fn new_opt(val: i32) -> Option<Self> { Some(Positivei32 { val }) } }
Tracking the Field Value
In addition to letting us constrain the underlying i32 to be positive,
the n: int index lets flux precisely track the value of the Positivei32.
For example, we can say that the following function returns a very specific Positivei32:
#[spec(fn() -> Positivei32[{n:10}])] fn mk_positive_10() -> Positivei32 { Positivei32 { val: 10 } }
(When there is a single index, we can just write Positivei32[10].)
Since the field val corresponds to the tracked index,
flux "knows" what val is from the index, and hence lets us check that
#[spec(fn() -> i32[10])] fn test_ten() -> i32 { let p = mk_positive_10(); // p : Positivei32[{n: 10}] let res = p.val; // res : i32[10] res }
Tracking the Value in the Constructor
EXERCISE Scroll back up, and modify the spec for new
so that the below code verifies. That is, modify the spec
so that it says what the value of val is when new returns
a Positivei32. You will likely need to combine indexes
and constraints as shown in the example add_points.
#[spec(fn() -> i32[99])] fn test_new() -> i32 { let p = Positivei32::new(99); let res = p.val; res }
Field vs. Index?
At this point, you might be wondering why, since n is the value of the field val,
we didn't just name the index val instead of n?
Indeed, we could have named it val.
However, we picked a different name to emphasize that the index is distinct from the field. The field actually exists at run-time, but in contrast, the index is a type-level property that only lives at compile-time.
Integers in a Range
Of course, once we can index and constrain a single field, we can do so for many fields.
For instance, suppose we wanted to write a Range type with two fields start and end
which are integers such that start <= end. We might do so as
#[refined_by(start: int, end: int)] #[invariant(start <= end)] struct Range { #[field(i32[start])] start: i32, #[field(i32[end])] end: i32, }
Note that this time around, we're using the same names for the index as the field names (even though they are conceptually distinct things).
Legal Ranges
Again, the refined struct specification will ensure we only create legal Range values.
fn test_range() { vec![ Range { start: 0, end: 10 }, // ok Range { start: 15, end: 5 }, // rejected! ]; }
A Range Constructor
EXERCISE Fix the specification of the new
constructor for Range so that both new and
test_range_new are accepted by flux. (Again,
you will need to combine indexes and constraints
as shown in the example add_points.)
impl Range { pub fn new(start: i32, end: i32) -> Self { Range { start, end } } } #[spec(fn() -> Range[{start: 0, end: 10}])] fn test_range_new() -> Range { let rng = Range::new(0, 10); assert(rng.start == 0); assert(rng.end == 10); rng }
Combining Ranges
Lets write a function that computes the union of two ranges.
For example, given the range from 10-20 and 15-25, we might
want to return the the union is 10-25.
fn min(x:i32, y:i32) -> i32 { if x < y { x } else { y } } fn max(x:i32, y:i32) -> i32 { if x < y { y } else { x } } fn union(r1: Range, r2: Range) -> Range { let start = min(r1.start, r2.start); let end = max(r2.end, r2.end); Range { start, end } }
EXERCISE Can you figure out how to fix the spec for min and max
so that flux will accept that union only constructs legal Range values?
Refinement Functions
When code get's more complicated, we like to abstract it into reusable
functions. Flux lets us do the same for refinements too. For example, we
can define refinement-level functions min and max which take int
(not i32 or usize but logical int) as input and return that as output.
defs! { fn min(x: int, y: int) -> int { if x < y { x } else { y } } fn max(x: int, y: int) -> int { if x < y { y } else { x } } }
We can now use refinement functions like min and max inside types.
For example, the output type of decr precisely tracks the decremented value.
impl Positivei32 { #[spec(fn(&Self[@p]) -> Self[max(1, p.n - 1)])] fn decr(&self) -> Self { let val = if self.val > 1 { self.val - 1 } else { self.val }; Positivei32 { val } } } fn test_decr() { let p = Positivei32{val: 2}; // p : Positivei32[2] assert(p.val == 2); let p = p.decr(); // p : Positivei32[1] assert(p.val == 1); let p = p.decr(); // p : Positivei32[1] assert(p.val == 1); }
Combining Ranges, Precisely
EXERCISE The union function that we wrote
above says some Range is returned, but nothing
about what that range actually is! Fix the spec
for union below, so that flux accepts test_union below.
impl Range { #[spec(fn(&Self[@r1], &Self[@r2]) -> Self)] pub fn union(&self, other: &Range) -> Range { let start = if self.start < other.start { self.start } else { other.start }; let end = if self.end < other.end { other.end } else { self.end }; Range { start, end } } } fn test_union() { let r1 = Range { start: 10, end: 20 }; let r2 = Range { start: 15, end: 25 }; let r3 = r1.union(&r2); assert(r3.start == 10); assert(r3.end == 25); }
Summary
To conclude, we saw how you can use flux to refine user-defined struct to track,
at the type-level, the values of fields, and to then constrain the sets of legal
values for those structs.
To see a more entertaining example, check out this code
which shows how we can use refinements to ensure that only legal Dates can be constructed
at compile time!
Refining Enums
Previously we saw how to refine structs to constrain the space
of legal values, for example, to define a Positivei32 or a Range struct where
the start was less than or equal to the end. Next, lets see how the same mechanism
can be profitably used to let us check properties of enums at compile time.
Failure is an Option
Rust's type system is really terrific for spotting all manner of bugs at compile time. However, that just makes it all the more disheartening to get runtime errors like
thread ... panicked at ... called `Option::unwrap()` on a `None` value
Lets see how to refine enum's like Option to
let us unwrap without the anxiety of run-time failure.
A Refined Option
To do so, lets define a custom Option type 1 that
is indexed by a bool which indicates whether or not
the option is valid (i.e. Some or None):
#[refined_by(valid: bool)] enum Option<T> { #[variant((T) -> Option<T>[{valid: true}])] Some(T), #[variant(Option<T>[{valid: false}])] None, }
As with std::option::Option, we have two variants
Some, with the "payload"TandNone, without.
However, we have tricked out the type in two ways.
- First, we added a
boolsorted index that aims to track whether the option isvalid; - Second, we used the
variantattribute to specify the value of the index for theSomeandNonecases.
Constructing Options
The definition above tells flux that Some(...)
has the refined type Option<...>[{valid: true}],
and None has the refined type Option<...>[{valid: false}].
NOTE When there is a single refinement index, we can skip the {valid:b}
and just write b.
#[spec(fn () -> Option<i32>[true])] fn test_some() -> Option<i32> { Option::Some(12) } #[spec(fn () -> Option<i32>[false])] fn test_none() -> Option<i32> { Option::None }
Destructing Options by Pattern Matching
The neat thing about refining variants is that pattern matching
on the enum tells flux what the variant's refinements are.
For example, consider the following implementation of is_some
impl<T> Option<T> { #[spec(fn(&Self[@valid]) -> bool[valid])] pub fn is_some(&self) -> bool { match self { Option::Some(_) => true, // self : &Option<..>[true] Option::None => false, // self : &Option<..>[false] } } }
Never Do This!
When working with Option types, or more generally,
with enums, we often have situations in pattern-match
cases where we "know" that that case will not arise.
Typically we mark those cases with an unreachable!() call.
With flux, we can do even more: we can prove, at compile-time, that those cases will never, in fact, be executed.
#[spec(fn () -> _ requires false)] fn unreachable() -> ! { assert(false); // flux will prove this is unreachable unreachable!(); // panic if we ever get here }
The precondition false ensures that the only way that
a call to unreachable can be verified is when flux can prove
that the call-site is "dead code".
fn test_unreachable(n: usize) { let x = 12; // x : usize[12] let x = 12 + n; // x : usize[12 + n] where 0 <= n if x < 12 { unreachable(); // impossible, as x >= 12 } }
Unwrap Without Anxiety!
Lets use our refined Option to implement a safe unwrap function.
impl <T> Option<T> { #[spec(fn(Self[true]) -> T)] pub fn unwrap(self) -> T { match self { Option::Some(v) => v, Option::None => unreachable(), } } }
The spec requires that unwrap is only called
with an Option whose (valid) index is true,
i.e. Some(...).
The None pattern is matched only when the index
is false which is impossible, as it contradicts
the precondition.
Hence, flux concludes that pattern is dead code
(like the x < 12 branch is dead code in the
test_unreachable above.)
Using unwrap
Next, lets see some examples of how to use refined options
to safely unwrap.
Safe Division
Here's a safe divide-by-zero function that returns an Option<i32>:
#[spec(fn(n:i32, k:i32) -> Option<i32>)] pub fn safe_divide(n: i32, k: i32) -> Option<i32> { if k > 0 { Option::Some(n / k) } else { Option::None } }
EXERCISE Why does the test below fail to type check?
Can you fix the spec for safe_divide so flux is happy
with test_safe_divide?
fn test_safe_divide() -> i32 { safe_divide(10, 2).unwrap() }
Smart Constructors Revisited
Recall the struct Positivei32
and the smart constructor we wrote for it.
#[refined_by(n: int)] #[invariant(n > 0)] struct Positivei32 { #[field(i32[n])] val: i32 } impl Positivei32 { #[spec(fn(val: i32) -> Option<Self>)] pub fn new(val: i32) -> Option<Self> { if val > 0 { Option::Some(Positivei32 { val }) } else { Option::None } } }
EXERCISE The code below has a function that
invokes the smart constructor and then unwraps
the result. Why is flux complaining? Can you fix
the spec of new so that the test_unwrap figure
out how to fix the spec of new so that test_new_unwrap
is accepted?
fn test_new_unwrap() { Positivei32::new(10).unwrap(); }
TypeStates: A Refined Timer
Lets look a different way to use refined enums.
On the flux zulip we were asked
if we could write an enum to represent a Timer
with two variants:
Inactiveindicating that the timer is not running, andCountDown(n)indicating that the timer is counting down fromnseconds.
Somehow using refinements to ensure that the timer can only
be set to Inactive when n < 1.
Refined Timers
To do so, lets define the Timer, refined with an int index that tracks
the number of remaining seconds.
#[flux::refined_by(remaining: int)] enum Timer { #[flux::variant(Timer[0])] Inactive, #[flux::variant((usize[@n]) -> Timer[n])] CountDown(usize) }
The flux definitions ensure that Timer has two variants
Inactive, which has aremainingindex of0, andCountDown(n), which has aremainingindex ofn.
Timer Implementation
We can now implement the Timer with a constructor and a method to set it to Inactive.
impl Timer { #[spec(fn (n: usize) -> Timer[n])] pub fn new(n: usize) -> Self { Timer::CountDown(n) } #[spec(fn (self: &mut Self[0]))] fn deactivate(&mut self) { *self = Timer::Inactive } }
Deactivate the Timer
Now, you can see that flux will only let us set_inactive
a timer whose countdown is at 0.
#![allow(unused)] fn main() { fn test_deactivate() { let mut t0 = Timer::new(0); t0.deactivate(); // verifies let mut t3 = Timer::new(3); t3.deactivate(); // rejected } }
Ticking the Timer
Here is a function to tick the timer down by one second.
impl Timer { #[spec(fn (self: &mut Self[@s]) ensures self: Self)] fn tick(&mut self) { match self { Timer::CountDown(s) => { let n = *s; if n > 0 { *s = n - 1; } } Timer::Inactive => {}, } } }
EXERCISE Can you fix the spec for tick so that flux accepts the following test?
fn test_tick() { let mut t = Timer::new(3); t.tick(); // should decrement to 2 t.tick(); // should decrement to 1 t.tick(); // should decrement to 0 t.deactivate(); // should set to Inactive }
Summary
In this chapter, we saw how you refine an enum with indices, and then specify
the values of the indices for each variant. This let us, for example, determine
whether an Option is Some or None at compile time, and to safely unwrap
the former, and to encode a "typestate" mechanism for a Timer that tracks how
many seconds remain in a countdown, ensuring we only deactivate when the timer
has expired.
You can do various other fun things, like
- track the length of a linked list or
- track the set of elements in the list, or
- determine whether an expression is in normal form, or
- ensure the layers of a neural network are composed correctly.
-
In the chapter on extern specifications we will explain how to "retrofit" these refinements onto the existing
std::option::Optiontype. ↩
Opaque Types: Refined Vectors
While rustc has a keen eye for spotting nasty bugs at
compile time, it is not omniscient. We've all groaned in
dismay at seeing deployed code crash with messages like
panicked at 'index out of bounds: the len is ... but the index is ...'
Next, lets see how flux's refinement and ownership mechanisms let us write a refined vector API whose types track vector sizes and ensure --- at compile time --- that vector accesses cannot fail at runtime.
Refining Vectors ...
To track sizes, lets define a struct that
is just a wrapper around the std::vec::Vec
type, but with a refinement index that tracks
the size of the vector.
#[opaque] #[refined_by(len: int)] pub struct RVec<T> { inner: Vec<T>, }
... to Track their Size
As with other structs we're using refined_by
to index the RVec with an int value (that will represent
the vector's length.)
The idea is that
RVec<i32>[10]represents a vector ofi32size 10, andRVec<bool>{v:0 < v}represents a non-empty vector ofbool, andRVec<RVec<f32>[n]>[m]represents a vector of vectors off32of sizemand each of whose elements is a vector of sizen.
... but Opaquely
The opaque attribute tells flux that we're not
going to directly connect the len to any of
the RVec's fields' values.
This is quite unlike Positivei32 example
where the index held the actual value of the field,
or the Timer example where the
index held the value of the countdown.
Instead, with an opaque struct the idea is that the value
of the index will be tracked solely by the API for that struct.
Next, lets see how to build such an API for creating and
manipulating RVec, where the length is precisely tracked
in the index.
Creating Vectors
I suppose one must start with nothing: the empty vector.
#[trusted] impl<T> RVec<T> { #[spec(fn() -> RVec<T>[0])] pub fn new() -> Self { Self { inner: Vec::new() } } }
The above implements RVec::new as a wrapper around Vec::new.
The #[trusted] attribute tells flux to not check this code,
i.e. to simply trust that the specification is correct.
Indeed, flux cannot check this code.
If you remove the #trusted (do it!) then flux will
complain that you cannot access the inner field
of the opaque struct!
So the only way to use an RVec is to define a "trusted" API,
and then use that in client code, where for example, callers
of RVec::new get back an RVec indexed with 0 : the empty vector.
Pushing Values
An empty vector is a rather desolate thing.
To be of any use, we need to be able to push
values into it, like so
#[trusted] impl<T> RVec<T> { #[spec(fn(self: &mut RVec<T>[@n], T) ensures self: RVec<T>[n+1])] pub fn push(&mut self, item: T) { self.inner.push(item); } }
The refined type for push says that it takes a updatable reference to an RVec<T> of size n and, a value T
and ensures that upon return, the size of self is increased by 1.
Creating a Vector with push
Lets test that the types are in fact tracking sizes.
#[spec(fn () -> RVec<i32>[3])] fn test_push() -> RVec<i32> { let mut v = RVec::new(); // v: RVec<i32>[0] v.push(1); // v: RVec<i32>[1] v.push(2); // v: RVec<i32>[2] v.push(3); // v: RVec<i32>[3] v }
EXERCISE: Can you correctly implement the code
for zeros so that it typechecks?
#[spec(fn(n: usize) -> RVec<i32>[n])] fn zeros(n:usize) -> RVec<i32> { let mut v = RVec::new(); // v: RVec<i32>[0] let mut i = 0; while i <= n { v.push(0); // v: RVec<i32>[i] i += 1; } v }
Popping Values
Not much point stuffing things into a vector if we can't get them out again.
For that, we might implement a pop method that returns the last element
of the vector.
Aha, but what if the vector is empty? You could return an
Option<T> or since we're tracking sizes, we could
require that pop only be called with non-empty vectors.
#[trusted] impl<T> RVec<T> { #[spec(fn(self: &mut {RVec<T>[@n] | 0 < n}) -> T ensures self: RVec<T>[n-1])] pub fn pop(&mut self) -> T { self.inner.pop().unwrap() } }
Note that unlike push which works for any RVec<T>[@n], the pop
method requires that 0 < n i.e. that the vector is not empty.
Using the push/pop API
Now already flux can start checking some code, for example if you push two
elements, then you can pop twice, but flux will reject the third pop at
compile-time
fn test_push_pop() { let mut vec = RVec::new(); // vec: RVec<i32>[0] vec.push(10); // vec: RVec<i32>[1] vec.push(20); // vec: RVec<i32>[2] vec.pop(); // vec: RVec<i32>[1] vec.pop(); // vec: RVec<i32>[0] vec.pop(); // rejected! }
In fact, the error message from flux will point to exact condition that
does not hold
#![allow(unused)] fn main() { error[FLUX]: precondition might not hold | 24 | v.pop(); | ^^^^^^^ call site | = note: a precondition cannot be proved at this call site note: this is the condition that cannot be proved | 78 | #[spec(fn(self: &mut{RVec<T>[@n] | 0 < n}) -> T | ^^^^^ }
Querying the Size
Perhaps we should peek at the size of the vector
to make sure its not empty before we pop it.
We can do that by writing a len method that returns
a usize corresponding to (and hence, by indexed by)
the size of the input vector
#[flux_rs::trusted] impl<T> RVec<T> { #[spec(fn(&RVec<T>[@vec]) -> usize)] pub fn len(&self) -> usize { self.inner.len() } }
EXERCISE Can you fix the spec for len so that the code below
verifies, i.e. so that flux "knows" that
- after two
pushes, the value returned by.len()is exactly2, and - after two
pops the size is0again.
fn test_len() { let mut vec = RVec::new(); vec.push(10); vec.push(20); assert(vec.len() == 2); vec.pop(); vec.pop(); assert(vec.len() == 0); }
Random Access
Of course, vectors are not just stacks, they also allow random access to their elements which is where those pesky panics occur, and where the refined vector API gets rather useful.
Now that we're tracking sizes, we can require
that the method to get an element only be called
with a valid index less than the vector's size
impl<T> RVec<T> { #[spec(fn(&RVec<T>[@n], i: usize{i < n}) -> &T)] pub fn get(&self, i: usize) -> &T { &self.inner[i] } #[spec(fn(&mut RVec<T>[@n], i: usize{i < n}) -> &mut T)] pub fn get_mut(&mut self, i: usize) -> &mut T { &mut self.inner[i] } }
Summing the Elements of an RVec
EXERCISE Can you spot and fix the off-by-one error
in the code below which loops over the elements
of an RVec and sums them up? 1
fn sum_vec(vec: &RVec<i32>) -> i32 { let mut res = 0; let mut i = 0; while i <= vec.len() { res += vec.get(i); i += 1; } res }
Using the Index trait
Its a bit of an eyesore to to use get and get_mut directly.
Instead lets implement the Index and IndexMut
traits for RVec which allows us to use the [..]
operator to access elements
impl<T> std::ops::Index<usize> for RVec<T> { type Output = T; #[spec(fn(&RVec<T>[@n], i:usize{i < n}) -> &T)] fn index(&self, index: usize) -> &T { self.get(index) } } impl<T> std::ops::IndexMut<usize> for RVec<T> { #[spec(fn(&mut RVec<T>[@n], i:usize{i < n}) -> &mut T)] fn index_mut(&mut self, index: usize) -> &mut T { self.get_mut(index) } }
Summing Nicely
Now the above vec_sum example looks a little nicer
fn sum_vec_fixed(vec: &RVec<i32>) -> i32 { let mut res = 0; let mut i = 0; while i < vec.len() { res += vec[i]; i += 1; } res }
Memoization
Lets put the whole API to work in this "memoized" version of the fibonacci function which uses a vector to store the results of previous calls
pub fn fib(n: usize) -> i32 { let mut r = RVec::new(); let mut i = 0; while i < n { if i == 0 { r.push(0); } else if i == 1 { r.push(1); } else { let a = r[i - 1]; let b = r[i - 2]; r.push(a + b); } i += 1; } r.pop() }
EXERCISE Flux is unhappy with the pop at the end of the function
which returns the last value as the result: it thinks the vector
may be empty and so the pop call may fail ... Can you spot and fix
the problem?
#![allow(unused)] fn main() { error[FLUX]: precondition might not hold --> src/vectors.rs:40:5 | 40 | r.pop() | ^^^^^^^ }
Binary Search
As a last example, lets look at a simplified version of the
binary_search method from std::vec, into which
we've snuck a tiny little bug
pub fn binary_search(vec: &RVec<i32>, x: i32) -> Result<usize, usize> { let mut size = vec.len(); let mut left = 0; let mut right = size; while left <= right { let mid = left + size / 2; let val = vec[mid]; if val < x { left = mid + 1; } else if x < val { right = mid; } else { return Ok(mid); } size = right - left; } Err(left) }
Flux complains in two places
#![allow(unused)] fn main() { error[FLUX]: precondition might not hold --> src/vectors.rs:152:19 | 152 | let val = vec[mid]; | ^^^^^^^^ call site | = note: a precondition cannot be proved at this call site note: this is the condition that cannot be proved --> src/rvec.rs:189:44 | 189 | #[spec(fn(&RVec<T>[@n], usize{v : v < n}) -> &T)] | ^^^^^ error[FLUX]: arithmetic operation may overflow --> src/vectors.rs:160:9 | 160 | size = right - left; | ^^^^^^^^^^^^^^^^^^^ }
-
The vector access may be unsafe as
midcould be out of bounds! -
The
sizevariable may underflow asleftmay exceedright!
EXERCISE Can you the spot off-by-one and figure out a fix?
Summary
Well then. We just saw how Flux's index and constraint mechanisms combine with Rust's ownership to let us write a refined vector API that ensures the safety of all accesses at compile time.
These mechanisms are compositional : we can use standard
type machinery to build up compound structures and APIs from
simple ones, as we will see when we use RVec to implment
sparse matrices and a small
neural network library.
-
Why not use an iterator? We'll get there in due course! ↩
Const Generics
Rust has a built-in notion of arrays : collections of objects of
the same type T whose size is known at compile time. The fact that
the sizes are known allows them to be allocated contiguously in memory,
which makes for fast access and manipulation.
When I asked ChatGPT what arrays were useful for, it replied
with several nice examples, including low-level systems programming (e.g.
packets of data represented as structs with array-valued fields), storing configuration data, or small sets of related values (e.g. RGB values for a pixel).
#![allow(unused)] fn main() { type Pixel = [u8; 3]; // RGB values let pix0: Pixel = [255, 0, 127]; let pix1: Pixel = [ 0, 255, 127]; }
Compile-time Safety...
As the size of the array is known at compile time, Rust can make sure that we don't create arrays of the wrong size, or access them out of bounds.
For example, rustc will grumble if you try to make a Pixel with 4 elements:
#![allow(unused)] fn main() { | 52 | let pix2 : Pixel = [0,0,0,0]; | ----- ^^^^^^^^^ expected an array with a fixed size of 3 elements, found one with 4 elements | | | expected due to this }
Similarly, rustc will wag a finger if you try to access a Pixel at an invalid index.
#![allow(unused)] fn main() { | 54 | let blue0 = pix0[3]; | ^^^^^^^ index out of bounds: the length is 3 but the index is 3 | }
... Run-time Panic!
However, the plain type system works only upto a point. For example, consider the
following function to compute the average color value of a collection of &[Pixel]
#![allow(unused)] fn main() { fn average_color(pixels: &[Pixel], i: usize) -> u64 { let mut sum = 0; for p in pixels { sum += p[i] as u64; } sum / pixels.len() as u64 } }
Now, rustc will not complain about the above code, even though it may panic if
color is out of bounds (or of course, if the slice pixels is empty!).
For example, the following code
fn main() { let pixels = [ [255, 0, 0], [0, 255, 0], [0, 0, 255] ]; let avg = average(&pixels, 3); println!("Average: {}", avg); }
panics at runtime:
thread 'main' panicked ... index out of bounds: the len is 3 but the index is 3
Refined Compile-time Safety
Fortunately, flux knows about the sizes of arrays and slices. At compile time,
flux warns about two possible errors in average_color
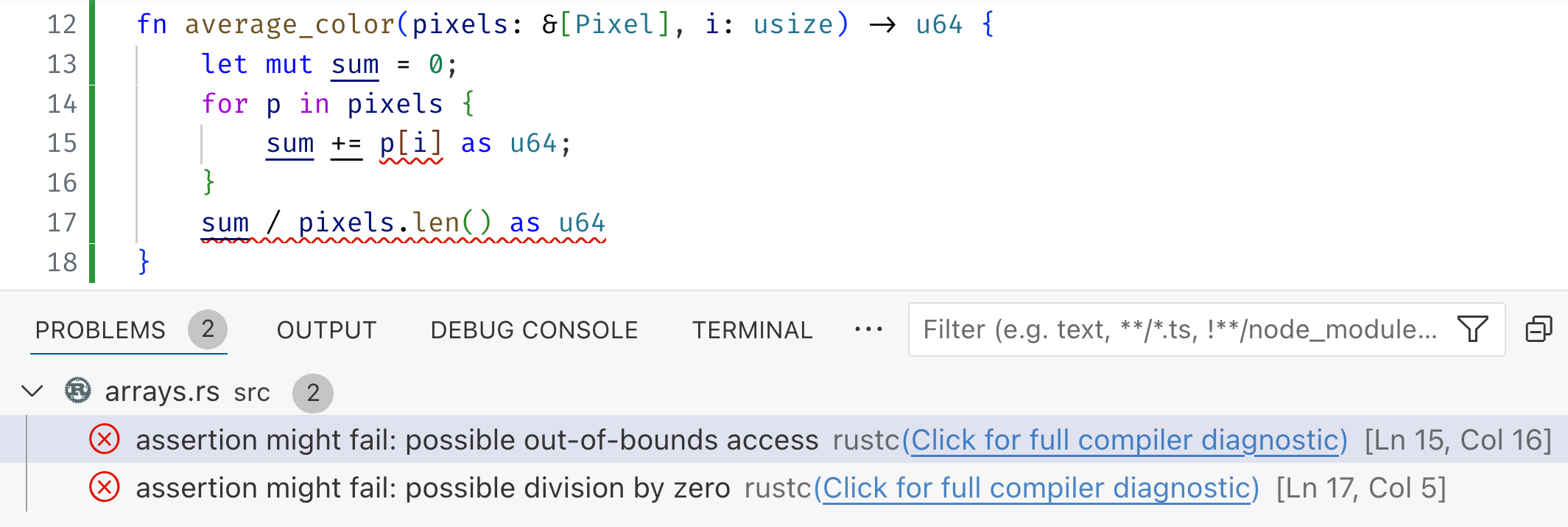
- The index
imay be out of bounds when accessingp[i]and - The division can panic as
pixelsmay be empty (i.e. have length0).
We can fix these errors by requiring that the input
ibe a valid color index, i.e.i < 3andpixelsbe non-empty, i.e. have sizenwheren > 0
#![allow(unused)] fn main() { #[spec(fn(pixels: &[Pixel][@n], i:usize{i < 3}) -> u64 requires n > 0)] }

Const Generics
Rust also lets us write arrays that are generic over the size. For example,
suppose we want to take two input arrays x and y of the same size N and
compute their dot product. We can write
#![allow(unused)] fn main() { fn dot<const N:usize>(x: [f32;N], y: [f32;N]) -> f32 { let mut sum = 0.0; for i in 0..N { sum += x[i] * y[i]; } sum } }
This is very convenient because rustc will prevent us from calling dot with
arrays of different sizes, for example we get a compile-time error
#![allow(unused)] fn main() { | 68 | dot([1.0, 2.0], [3.0, 4.0, 5.0]); | --- ^^^^^^^^^^^^^^^ expected an array with a fixed size of 2 elements, found one with 3 elements | | | arguments to this function are incorrect | }
However, suppose we wanted to compute the dot product of just the first k elements
#![allow(unused)] fn main() { fn dot_k<const N:usize>(x: [f32;N], y: [f32;N], k: usize) -> f32 { let mut sum = 0.0; for i in 0..k { sum += x[i] * y[i]; } sum } }
Now, unfortunately, rustc will not prevent us from calling dot_k with k set to a value that is too large!
#![allow(unused)] fn main() { thread 'main' panicked at ... index out of bounds: the len is 2 but the index is 2 }
Yikes.
Refined Const Generics
Fortunately, flux understands const-generics as well!
First off, it warns us about the fact that the accesses with the index may be out of bounds.

We can fix it in two ways.
- The permissive approach is to accept any
kbut restrict the iteration to the valid elements
#![allow(unused)] fn main() { fn dot_k<const N:usize>(x: [f32;N], y: [f32;N], k: usize) -> f32 { let mut sum = 0.0; let n = if k < N { k } else { N }; for i in 0..n { sum += x[i] * y[i]; } sum } }

- The strict approach is to require that
kbe less than or equal toN
#![allow(unused)] fn main() { #[spec(fn(x: [f32;N], y: [f32;N], k:usize{k <= N}) -> f32)] fn dot_k<const N:usize>(x: [f32;N], y: [f32;N], k: usize) -> f32 { let mut sum = 0.0; for i in 0..k { sum += x[i] * y[i]; } sum } }

Do you understand why
(1) Adding the type signature moved the error from the body of dot_k into the call-site inside test?
(2) Then editing test to call dot_k with k=2 fixed the error?
Summary
Rust's (sized) arrays are great, and flux's refinements make them even better,
by ensuring indices are guaranteed to be within the arrays bounds. Const generics
let us write functions that are polymorphic over array sizes, and again, refinements
let us precisely track those sizes to prevent out-of-bounds errors!
Extern Specifications
#![feature(allocator_api)] #![allow(unused)] extern crate flux_rs; use flux_rs::{attrs::*, extern_spec}; use std::alloc::{Allocator, Global}; use std::mem::swap;
No man is an island.
Every substantial Rust code base will make use of external crates. To check properties of such code bases, Flux requires some way to reason about the uses of the external crate's APIs.
Let's look at how Flux lets you write assumptions1 about the behavior of those libraries via extern specifications (abbreviated to extern-specs) which can then let us check facts about the uses of the external crate's APIs.
To this end, flux lets you write extern-specs for
- Functions,
- Structs,
- Enums,
- Traits and their Impls.
In this chapter, we'll look at the first three, and then we'll see how the idea extends to traits and their implementations.
Extern Specs for Functions
As a first example, lets see how to write an extern spec for
the function std::mem::swap.
Using Extern Functions
Lets write a little test that creates to references and swaps them
pub fn test_swap() { let mut x = 5; let mut y = 10; std::mem::swap(&mut x, &mut y); assert(x == 10); assert(y == 5); }
Now, if you push the play button you should see that Flux cannot prove
the two asserts. The little red squiggles indicate it does not know that
after the swap the values of x and y are swapped to 10 and 5, as,
well, it has no idea about how swap behaves!
Writing Extern Specs
We can fill this gap in flux's understanding by providing
an extern-spec that gives flux a refined type
specification for swap
#[extern_spec] // UNCOMMENT THIS LINE to verify `test_swap` // #[spec(fn(x: &mut T[@vx], y: &mut T[@vy]) ensures x: T[vy], y: T[vx])] fn swap<T>(a: &mut T, b: &mut T);
The refined specification says that swap takes as input
two mutable references x and y that refer to values of
type T with respective indices vx and vy. Upon finishing,
the types referred to by x and y are "swapped".
Now, if you uncomment and push play, flux will verify test_swap as
it knows that at the call-site, vx and vy are respectively 5 and 10.
Features of Extern Spec Functions
Note two things about the extern_spec specification.
- First, up at the top, we had to import the
extern_specmacro, implemented in theflux_rscrate, - Second, importantly, we do not write an implementation for the function,
as that is going to be taken from
std::mem. Instead, we're just telling flux to use the (uncommented) type specification when checking clients.
Getting the Length of a Slice
Here is a function below that returns the first (well, 0th)
element of a slice of u32s.
fn first(slice: &[u32]) -> Option<u32> { let n = slice.len(); if n > 0 { Some(slice[0]) } else { None } }
EXERCISE Unfortunately, flux does not know what slice.len() returns, and
so, cannot verify that the access slice[0] is safe! Can you help
it by fixing the extern_spec for the method shown below?
You might want to refresh your memory about the meaning of
&[T][@n] by quickly skimming the previous chapter on the sizes of arrays
and slices.
#[extern_spec] impl<T> [T] { #[spec(fn(&[T][@n]) -> usize)] fn len(v: &[T]) -> usize; }
Extern Specs for Enums: Option
In the chapter on enums we saw how you can
refine enum types with extra indices that track extra information
about the underlying value. For example, we saw how to implement
a refined Option that is indexed
by a boolean that tracks whether the value is Some (and hence, safe
to unwrap)or None.
The extern_spec mechanism lets us do the same thing, but directly on
std::option::Option. To do so we need only
- write extern-specs for the enum definition that add the indices and connect them to the variant constructors,
- write extern-specs for the method signatures that let us use the indices to describe a refined API that is used to check client code.
Extern Specs for the Type Definition
First, lets add the bool index to the Option type definition.
#[extern_spec] #[refined_by(valid: bool)] enum Option<T> { #[variant(Option<T>[{valid: false}])] None, #[variant((T) -> Option<T>[{valid: true}])] Some(T), }
As you might have noticed, this bit is identical
to the refined version of Option that we saw in
the chapter on enums,
except for the #[extern_spec] topping.
Using the Type Definition
Adding the above "retrofits" the bool index directly
into the std::option::Option type. So, for example
we can write
#[spec(fn () -> Option<i32>[{valid: true}])] fn test_some() -> Option<i32> { Some(42) } #[spec(fn () -> Option<i32>[{valid: false}])] fn test_none() -> Option<i32> { None }
TIP: When there is a single field like valid
you can drop it, and just write Option<i32>[true]
or Option<i32>[false].
Extern Specs for Impl Methods
The extern specs become especially useful when we use them to refine
the methods that implement various key operations on Options.
To do so, we can make an extern_spec impl for Option, much like
we did for slices, back here.
#[extern_spec] impl<T> Option<T> { #[spec(fn(&Option<T>[@b]) -> bool[b])] const fn is_some(&self) -> bool; #[spec(fn(&Option<T>[@b]) -> bool[!b])] const fn is_none(&self) -> bool; #[spec(fn(Option<T>[true]) -> T)] const fn unwrap(self) -> T; }
The definition looks rather like the actual one,
except that it wears the #[extern_spec] attribute
on top, and the methods have no definitions, as we
want to use those from the extern crate, in this case,
the standard library.
Notice that the spec for
is_somereturnstrueif the inputOptionwas indeedvalid, i.e. was aSome(..);is_nonereturnstrueif the inputOptionwas notvalid, i.e. was aNone.
Using Extern Method Specifications
We can test these new specifications out in our client code.
fn test_opt_specs(){ let a = Some(42); assert(a.is_some()); let b: Option<i32> = None; assert(b.is_none()); }
Safely Unwrapping
Of course, we all know that we shouldn't directly use unwrap.
However, sometimes, its ok, if we somehow know that the value
is indeed a valid Some(..). The refined type for unwrap keeps
us honest with a precondition that tells flux that it should
only be invoked when the underlying Option can be provably
valid.
#[spec(fn (n:u32) -> Option<u8>)] fn into_u8(n: u32) -> Option<u8> { if n <= 255 { Some(n as u8) } else { None } } fn test_unwrap() -> u8 { into_u8(42).unwrap() }
EXERCISE The function test_unwrap above
merrily unwraps the result of the call into_u8.
Flux is unhappy and flags an error even though surely
the call will not panic! The trouble is that the "default"
spec for into_u8 -- the Rust type -- says it can
return any Option<i32>, including those that might
well blow up unwrap. Can you fix the spec for into_u8
so that flux verifies test_unwrap?
A Safe Division Function
Lets write a safe-division function, that checks if the divisor is non-zero before doing the division.
#[spec(fn (num: u32, denom: u32) -> Option<u32[num / denom]>)] pub fn safe_div(num: u32, denom: u32) -> Option<u32> { if denom == 0 { None } else { Some(num / denom) } }
EXERCISE The client test_safe_div shown below is certainly it is safe to
divide by two! Alas, Flux thinks otherwise: it cannot determine that output of
safe_div may be safely unwrapped. Can you figure out how to fix the specification
for safe_div so that the code below verifies?
pub fn test_safe_div() { let res = safe_div(42, 2).unwrap(); assert(res == 21); }
Extern Specs for Structs: Vec
Previously, we saw how to define a new type RVec<T>
for refined vectors and to write
an API that let us track the vector's size, and hence
check the safety of vector accesses at compile time.
Next, lets see how we can use extern_spec to implement
(most of) the refined API directly on structs like
std::vec::Vec which are defined in external crates.
Extern Specs for the Type Definition
As with enums we start by sprinkling refinement
indices on the struct definition. Since we want
to track sizes, lets write
#[extern_spec] #[refined_by(len: int)] #[invariant(0 <= len)] struct Vec<T, A: Allocator = Global>;
Extern Invariants
Note that we can additionally attach invariants to the struct
definition, which correspond to facts that are always true about
the indices, for example, that the len of a Vec is always non-negative.
Extern structs are Opaque
Unlike with enum, the extern_spec is oblivious
to the internals of the struct. That is flux
assumes that the fields are all "private", and so the
refinements must be tracked solely using the methods
used to construct and manipulate the struct.
The simplest of these is the one that births an empty Vec
#[extern_spec] impl<T> Vec<T> { #[spec(fn() -> Vec<T>[0])] fn new() -> Vec<T>; }
We can test this out by creating an empty vector
#[spec(fn () -> Vec<i32>[0])] fn test_new() -> Vec<i32> { Vec::new() }
Extern Specs for Impl Methods
Lets beef up our refined Vec API with a few more methods
like push, pop, len and so on.
We might be tempted to just bundle them together with new
in the impl above, but it is important to Flux that the
the extern_spec implementations mirror the original
implementations so that Flux can accurately match (i.e. "resolve")
the extern_spec method with the original method, and thus,
attach the specification to uses of the original method.
As it happens, push and pop are defined in a separate
impl block, parameterized by a generic A: Allocator, so
our extern_spec mirrors this block:
#[extern_spec] impl<T, A: Allocator> Vec<T, A> { #[spec(fn(self: &mut Vec<T, A>[@n], T) ensures self: Vec<T, A>[n+1])] fn push(&mut self, value: T); #[spec(fn(self: &mut Vec<T, A>[@n]) -> Option<T> ensures self: Vec<T, A>[if n > 0 { n-1 } else { 0 }])] fn pop(&mut self) -> Option<T>; #[spec(fn(self: &Vec<T, A>[@n]) -> usize[n])] fn len(&self) -> usize; #[spec(fn(self: &Vec<T, A>) -> bool)] fn is_empty(&self) -> bool; }
Constructing Vectors
Lets take the refined vec API out for a spin.
#[spec(fn() -> Vec<i32>[3])] pub fn test_push() -> Vec<i32> { let mut res = Vec::new(); // res: Vec<i32>[0] res.push(10); // res: Vec<i32>[1] res.push(20); // res: Vec<i32>[2] res.push(30); // res: Vec<i32>[3] assert(res.len() == 3); res }
Flux uses the refinements to type res as a 0-sized Vec<i32>[0].
Each subsequent push updates the reference's type
by increasing the size by one.
Finally, the len returns the size at that point, 3, thereby
proving the assert.
Testing Emptiness
EXERCISE Can you fix the spec for is_empty above so that the
two assertions below are verified?
fn test_is_empty() { let v0 = test_new(); assert(v0.is_empty()); let v1 = test_push(); assert(!v1.is_empty()); }
The Refined vec! Macro
The ubiquitous vec! macro internally allocates a slice
and then calls into_vec to create a Vec.
#[extern_spec] impl<T> [T] { #[spec(fn(self: Box<[T], A>) -> Vec<T, A>)] fn into_vec<A>(self: Box<[T], A>) -> Vec<T, A> where A: Allocator; }
EXERCISE Can you fix the extern_spec for into_vec so that
the code below verifies?
#[spec(fn() -> Vec<i32>[3])] pub fn test_push_macro() -> Vec<i32> { let res = vec![10, 20, 30]; assert(res.len() == 3); res }
Pop-and-Unwrap
Suppose we wanted to write a function that popped the last element of a non-empty vector.
#[spec(fn (vec: &mut Vec<T>[@n]) -> T requires 0 < n ensures vec: Vec<T>[n-1])] fn pop_and_unwrap<T>(vec: &mut Vec<T>) -> T { vec.pop().unwrap() }
EXERCISE Flux chafes because the spec for pop is too weak:
above does not tell us when the returned value is safe to unwrap.
Can you go back and fix the spec for fn pop so that pop_and_unwrap
verifies?
PopPop!
EXERCISE Finally, as a parting exercise, can you work out
why flux rejects the pop2 function below, and modify the spec
so that it is accepted?
#[spec(fn (vec: &mut Vec<T>[@n]) -> (T, T) ensures vec: Vec<T>[n-2] )] fn pop2<T>(vec: &mut Vec<T>) -> (T, T) { let v1 = pop_and_unwrap(vec); let v2 = pop_and_unwrap(vec); (v1, v2) }
Summary
Previously, we saw how to attach refined specifications for functions, structs and enums.
In this chapter, we saw that you can use the extern_spec
mechanism to do the same things for objects defined elsewhere,
e.g. in external crates being used by your code.
Next, we'll learn how to use extern_spec to refine traits
(and their implementations), which is key to checking idiomatic
Rust code.
-
We say assumption because we're presuming that the actual code for the library is not available to verify; if it was, you could of course actually guarantee that the library correctly implements those specifications. ↩
Traits and Associated Refinements
#![allow(unused)] extern crate flux_rs; extern crate flux_core; extern crate flux_alloc; use flux_rs::{attrs::*, extern_spec}; use std::ops::Range;
One of Rust's most appealing features is its trait system which lets us decouple descriptions of particular operations that a type should support, from their actual implementations, to enable generic code that works across all implementations of an interface.
Traits are ubiquitous in Rust code. For example,
-
an addition
x + yis internally represented asx.add(y)wherexandycan be values that implement theAddtrait, allowing for a uniform way to write+that works across all compatible types; -
an indexing operation
x[i]is internally represented asx.index(i)wherexcan be any value that implements theIndextrait, andia compatible "key", which allows for a standard way to lookup containers at a particular value; -
an iteration
for x in e { ... }becomeswhile let Some(x) = e.next() { ... }, where theecan be any value that implements theIteratortrait, allowing for an elegant and uniform way to iterate over different kinds of ranges and collections.
In this chapter, lets learn how traits pose some interesting puzzles for formal verification, and how Flux resolves these challenges with associated refinements.
First things First
To limber up before we get to traits, lets write a function to return (a reference to) the first element of a slice.
fn get_first_slice<A>(container: &[A]) -> &A { &container[0] }
The method get_first_slice works just
fine if you call it on non-empty slices,
but will panic at run-time if you try it on
an empty one
fn test_first_slice() { let s0: &[i32] = &[10, 20, 30]; let v0 = get_first_slice(s0); println!("get_first_slice {s0:?} ==> {v0}"); let s1: &[char] = &['a', 'b', 'c']; let v1 = get_first_slice(s1); println!("get_first_slice {s1:?} ==> {v1}"); let s2: &[bool] = &[]; let v2 = get_first_slice(s2); println!("get_first_slice {s2:?} ==> {v2}"); }
Catching Panics at Compile Time
You might recall from this previous chapter that Flux tracks the sizes of arrays and slices.
If you click the check button, you will see that flux
disapproves of get_first_slice
error[E0999]: assertion might fail: possible out of bounds access
|
13 | &container[0];
| ^^^^^^^^^^^^
Specifying Non-Empty Slices
EXERCISE Can you go back and add a flux spec for get_first_slice that says that the function
should only be called with non-empty slices? The spec should look something like the below, except
the ... should be a constraint over size.
#[spec(fn (container: &[A]{size: ...}) -> &A)]
When you are done, you should see no warnings in get_first_slice but you will get an error in
test_first_slice, precisely at the location where we call it with an empty slice, which you
can fix by commenting out or removing the last call...
A Trait to Index Values
Next, lets write our own little trait to index different kinds of containers1.
pub trait IndexV1<Idx> { type Output:?Sized; fn index(&self, index: Idx) -> &Self::Output; }
The above snippet defines a trait called IndexV1 that is parameterized by Idx: the
type used as the actual index. To implement the trait, we must specify
- The
Selftype for the container itself (e.g. a slice, a vector, hash-map, a string, etc.), - The
Idxtype used as the index (e.g. ausizeorStringkey, orRange<usize>, etc), and - The
Output: an associated type that describes what theindexmethod returns, and finally, - The
indexmethod itself, which takes a reference toselfand anindexof typeIdx, and returns a reference to theOutput.
A Generic, Reusable get_firstV1
We can now write functions that work over any type that implements the Index trait.
For instance, we can generalize the get_first_slice method, which only worked on slices,
to the get_firstV1 method will let use borrow the 0th element of any container that
implements Index<usize>.
fn get_firstV1<A, T>(container: &T) -> &A where T: ?Sized + IndexV1<usize, Output = A> { container.index(0) }
Indexing Slices with usize
To use the trait, we must actually implement it for particular types of interest.
Lets implement a method to index a slice by a usize value:
#[trusted] impl <A> IndexV1<usize> for [A] { type Output = A; fn index(&self, index: usize) -> &Self::Output { &self[index] } }
The above code describes an implementation where the
Selftype of the container is a slice[A];Idxtype of the index isusize;Outputreturned byindex()is a (reference to)A; andindex()is just a wrapper around the standard library's implementation.
Lets ignore the #[trusted] for now: it just tells flux to accept this code
without protesting about self[index] triggering an out-of-bounds error.
Testing get_firstV1
Sweet! Now that we have a concrete implementation for Index
we should be able to test it
fn test_firstV1() { let s0: &[i32] = &[10, 20, 30]; let v0 = get_firstV1(s0); println!("get_firstV1 {s0:?} ==> {v0}"); let s1: &[char] = &['a', 'b', 'c']; let v1 = get_firstV1(s1); println!("get_firstV1 {s1:?} ==> {v1}"); let s2: &[bool] = &[]; let v2 = get_firstV1(s2); println!("get_firstV1 {s2:?} ==> {v2}"); }
Click the run button. Huh?! No warnings??
Of course, the last one will panic.
But why didn't flux warn us about it, like it did with test_first_slice.
Yikes get_firstV1 is unsafe!
When we directly access a slice as in get_first_slice,
or test_first_slice, flux complains about the potential,
in this case, certain, out of bounds access.
But the indirection through get_firstV1 (and index) has
has laundered the out of bounds access, tricking
flux into unsoundly missing the run-time error!
We're in a bit of a pickle.
The Index trait giveth the ability to write generic
code like get_firstV1, but apparently taketh away the
ability to catch panics at compile-time.
Surely, there is a way to use traits without giving up on compile-time verification...
The Challenge: How to Specify Safe Indexing, Generically
Clearly we should not call get_firstV1 with empty slices.
The method get_firstV1 wants to access the 0-th element
of the container, and will crash at run-time if the 0th element
does not exist, as is the case with an empty slice.
But the puzzle is this: how do we specify
"the 0-th element exists" for any
generic container that implements Index?
Associated Refinements
Flux's solution to this puzzle is to borrow a page from Rust's own playbook.
Lets revisit the definition of the Index trait:
pub trait IndexV1<Idx> {
type Output:?Sized;
fn index(&self, index: Idx) -> &Self::Output;
}In the above, Output is an associated type for the Index trait that
specifies what the index method returns. For instance, in our implementation
of Index<usize> for slices [A], the Output is A.
Inspired this idea, Flux extends traits with the ability to specify
associated refinements that can describe the values accepted
and returned by the trait's methods.
Valid Indexes
Thus, we can extend the trait with an associated refinement
that specifies when an index is valid for a container.
Lets do so by defining the Index trait as:
#[assoc(fn valid(me: Self, index: Idx) -> bool)] pub trait Index<Idx: ?Sized> { type Output: ?Sized; #[spec(fn(&Self[@me], idx: Idx{ Self::valid(me, idx) }) -> &Self::Output)] fn index(&self, idx: Idx) -> &Self::Output; }
There are two new things in our new version of Index.
1. Declaration
First, the assoc attribute declares2 the associated refinement:
a refinement level function named valid, that
- takes as inputs, the
Selftype of the container and theIdxtype of the index, and - returns a
boolwhich indicates if theindexis valid for the container.
2. Use
Next, the spec attribute refines the index method to say that it should only be
passed an idx that is valid for the me container, where valid is the associated
refinement declared above. The notation Self::valid(me, idx) is a
way to refer to the valid associated refinement, similar to
how Self::Output is used to refer to the Output associated type.
A Safe (and Generic, Reusable) get_first
We can now write functions that work over any type that implements the Index trait,
but where flux will guarantee that index is safe to call. For example, lets revisit
the get_first method that returns the 0th element of a container.
// #[spec(fn (&T{ container: T::valid(container, 0) }) -> &A)] fn get_first<A, T>(container: &T) -> &A where T: ?Sized + Index<usize, Output = A> { container.index(0) }
Aha, now flux complains that the above is unsafe because we don't know that container
is actually valid for the index 0. To make it safe, we must add (uncomment!) the
flux specification in the line above. This spec says that get_first can only be called
with a container that is valid for the index 0.
Indexing Slices with usize
Lets now revisit that implementation of for slices using usize indexes.
#[assoc(fn valid(size: int, index: int) -> bool { index < size })] impl <A> Index<usize> for [A] { type Output = A; #[spec(fn(&Self[@me], idx:usize{ Self::valid(me, idx) }) -> &Self::Output)] fn index(&self, index: usize) -> &Self::Output { &self[index] } }
As with the trait definition, there are two new things in our implementation of Index for slices.
1. Implementation
First, we provide a concrete implementation of the associated refinement valid.
Recall that in flux, slices [A] are represented by their size at the refinement level.
Hence, the implementation of valid takes as parameters the size
of the slice and the index, and returns true exactly if
the index is less than the size.
2. Use
As with the trait method, the actual implementation of the index
method has been refined to say that it should only be passed an
idx that is valid for me at the specified idx.3
Testing get_first
Now, lets revisit our clients for get_first using the new Index trait.
fn test_first() { let s0: &[i32] = &[10, 20, 30]; let v0 = get_first(s0); println!("get_first {s0:?} ==> {v0}"); let s1: &[char] = &['a', 'b', 'c']; let v1 = get_first(s1); println!("get_first {s1:?} ==> {v1}"); let s2: &[bool] = &[]; let v2 = get_first(s2); println!("get_first {s2:?} ==> {v2}"); }
Hooray! Now, when you click the check button, flux will complain about the
last call to get_first because the slice s2 is not valid for the index 0!
To do so, flux specialized the specification of get_first (which required
container to be valid for 0) with the actual definition of valid for
slices (which requires that 0 < size) and the actual size for s2 (which is 0).
As 0 < 0 is false, flux rejects the code at compile time.
Indexing Strings with Ranges
The whole point of the Index trait is be able to index different kinds of
containers. Lets see how to implement Index for str using Range<usize> indexes,
which return sub-slices of the string.
#[assoc( fn valid(me: str, index: Range<int>) -> bool { index.start <= index.end && index.end <= str_len(me) } )] impl Index<Range<usize>> for str { type Output = str; #[spec(fn(&Self[@me], idx:Range<usize>{ Self::valid(me, idx) }) -> &Self::Output)] fn index(&self, idx: Range<usize>) -> &Self::Output { &self[idx.start..idx.end] } }
The implementation above, implements Index<Range<usize>> for str by
-
Defining the associated refinement
validto say that aRangeis valid for a string if thestartof the range is less than or equal to theend, and theendis less than or equal to the length of the string (which we get using the built-instr_lenfunction); -
Refining the specification of the
indexmethod to say that it should only be passed anindexthat is valid for the stringme; and the givenidx.
Now when we run flux on clients of this implementation, we can see that the first call is a valid sub-slice, but the second is not and hence, is rejected by flux.
fn test_str() { let cat = "caterpillar"; let sub = cat.index(0..6); // OK let sub = cat.index(0..19); // Error }
Flux produces the error pinpointing the problem:
error[E0999]: refinement type error
|
89 | let sub = cat.index(0..19); // Error
| ^^^^^^^^^^^^^^^^ a precondition cannot be proved
|
note: this is the condition that cannot be proved
|
74 | index.start <= index.end && index.end <= str_len(me)
| ^^^^^^^^^^^^^^^^^^^^^^^^
EXERCISE Can you modify the code above so that the second call to index
is accepted by flux?
Indexing Vectors with usize
EXERCISE Let's implement the Index trait for Vec using usize indexes.
The definition of valid is too permissive, can you modify it so that flux accepts
the below impl?
#[assoc(fn valid(me: Vec, index: int) -> bool { true })] impl <A:Copy> Index<usize> for Vec<A> { type Output = A; #[spec(fn(&Self[@me], index:usize{ Self::valid(me, index) }) -> &Self::Output)] fn index(&self, index: usize) -> &Self::Output { &self[index] } }
EXERCISE Let's write a client that uses the index on Vec
to compute a dot-product for two Vec<f64>. Can you fix the spec
for dot_vec so flux accepts it?
#[spec(fn(xs: &Vec<f64>, ys: &Vec<f64>) -> f64)] fn dot_vec(xs: &Vec<f64>, ys: &Vec<f64>) -> f64 { let mut res = 0.0; for i in 0..xs.len() { res += xs.index(i) * ys.index(i); } res }
Indexing Vectors with Ranges
EXERCISE Finally, lets extract sub-slices from vectors using Range<usize> indexes.
Why does flux reject the below impl? Can you edit the code so flux accepts it?
#[assoc( fn valid(me: Vec, idx: Range<int>) -> bool { true } )] impl <A> Index<Range<usize>> for Vec<A> { type Output = [A]; #[spec(fn(&Self[@me], idx: Range<usize>{ Self::valid(me, idx) }) -> &Self::Output)] fn index(&self, idx: Range<usize>) -> &Self::Output { &self[idx.start..idx.end] } }
Conclusion
In this chapter, we saw how traits can be extended with associated refinements
which let us declare refinements on the inputs and outputs of trait methods
(e.g. valid indexes) that are then implemented by each implementation of
the trait (e.g. the index is less than the slice size).
Associated refinements turn out to be an extremely useful mechanism, for example, they let us specify properties of commonly used operations like indexing and iteration, and more advanced properties like the semantics of sql queries 4 and the behavior of memory allocators 5.
-
The "real" ones in the standard library have a few more moving parts that would needlessly complicate our explanation of the interaction between traits and formal verification. ↩
-
validfunction is just a declaration: we do not specify an actual body as those will be filled in by the implementors of the trait. We could specify a default body forvalide.g. which always returnstrue, which can be over-ridden i.e. redefined by implementations, but we must be careful about what we choose as the default. ↩ -
By the way, it seems a little silly to repeat the spec for
indexdoesn't it? To be sound, Flux checks that the implementation needs to be a subtype of the trait method. We could for example, accept more inputs and produce fewer outputs. But in this case, it is simply a version of the trait specification, specialized to the particularSelfandIdxtypes of the implementation. ↩ -
See section 6.2 of this POPL 2025 paper for more details. ↩
-
See this SOSP 2025 paper for more details. ↩
Simple Access Control
Hopefully, by this point, you have a reasonable idea of the main tools that Flux provides for refining types to capture correctness requirements. In this, our first case study, lets see how to use those tools to implement a very simple role-based access control (RBAC) system, where Flux will check that only users with appropriate permissions are allowed to access different resources. In doing so, we’ll get some more practice with the tools we have already seen, and learn about various other aspects of Flux, including how to
-
Lift enum variants up into refinements,
-
Specifying equality using associated refinements,
-
Write detached specifications,
-
Define and use refinement-level functions.
Reflection
A bird flying high above our access-control system, or more plausibly, an LLM attempting to summarize its code, would observe that it consists of three main entities: users who want to access resources, roles that are assigned to each user, and the permissions that may be granted to each role.
Roles Lets suppose that we want to track three kinds of users:
administrators, members and guests. We might represent these three roles
using a Rust enum:
#[reflect] #[derive(Debug, Clone)] pub enum Role { Admin, Member, Guest, }
Reflection The key new bit in the definition of Role is the
#[reflect] attribute, which tells Flux that we intend to use variants
of this enum inside refinements. Why not just automatically reflect
all enums? Currently, only a very restricted subset of enums are
reflected: those whose variants take no parameters. Hence, Flux
requires us to explicitly mark such enums with the #[reflect]
attribute. For example, we can now write a function that checks if a
given role is an Admin and returns true if so, and false
otherwise.
#[spec(fn (&Role[@r]) -> bool[r == Role::Admin])] pub fn is_admin(r: &Role) -> bool { match r { Role::Admin => true, _ => false, } }
EXERCISE: Complete the specification and implementation of
is_guest below. You cannot use == (yet) because, well, just try to
use it and see what happens!
fn is_guest(r: &Role) -> bool { true }
When you are done, all the assert statements in the test_role
function should be verified by Flux.
fn test_role() { let admin = Role::Admin; let member = Role::Member; let guest = Role::Guest; assert(is_admin(&admin) && !is_admin(&member) && !is_admin(&guest)); assert(!is_guest(&admin) && !is_guest(&member) && is_guest(&guest)); }
Defining Equality
My love and appreciation of pattern-matching should not be questioned.
However, sometimes we just want an old-fashioned equality test, for
instance, to make is_admin and is_guest trivial one-liners instead
of all the ceremony of a function-call wrapped inside a match
statement. Despite my telling you not to use == above, I’m pretty
certain that you tried it anyway. Or perhaps you anticipated that you
could not use it because we have not yet implemented the PartialEq
trait for Role which is what Rust uses to implement == and !=
comparisons.
A Refined PartialEq Trait The Flux standard library refines std‘s
PartialEq trait with two associated refinements (see
this chapter) is_eq and is_ne that respectively specify when two
values of the type implementing PartialEq are equal or not. The
methods eq and ne return boolean values v such that the
predicate is_eq(r1, r2, v) and is_ne(r1, r2, v) hold. By default,
the two associated refinements are just true, meaning that the bool
result v is unconstrained: it can be either true or false
regardless of the inputs.
#![allow(unused)] fn main() { #[assoc( fn is_eq(x: Self, y: Rhs, v: bool) -> bool { true } fn is_ne(x: Self, y: Rhs, v: bool) -> bool { true } )] trait PartialEq<Rhs: PointeeSized = Self>: PointeeSized { #[spec(fn(&Self[@s], &Rhs[@t]) -> bool{v: Self::is_eq(s, t, v)})] fn eq(&self, other: &Rhs) -> bool; #[spec(fn(&Self[@s], &Rhs[@t]) -> bool{v: Self::is_ne(s, t, v)})] fn ne(&self, other: &Rhs) -> bool; } }
A Refined PartialEq Implementation However, for particular
implementations of PartialEq, e.g. for Role, we can define the
associated refinements to capture exactly when two values are equal or
not.
#[assoc( fn is_eq(x: Self, y: Self, res: bool) -> bool { res <=> (x == y) } fn is_ne(x: Self, y: Self, res: bool) -> bool { true } )] impl PartialEq for Role { #[spec(fn(&Self[@r1], &Self[@r2]) -> bool[r1 == r2])] fn eq(&self, other: &Self) -> bool { match (self, other) { (Role::Admin, Role::Admin) => true, (Role::Member, Role::Member) => true, (Role::Guest, Role::Guest) => true, _ => false, } } }
Now that we’ve implemented PartialEq, we can now write a simple
tests to check to see if Flux can understand when two Roles are equal
or not.
fn test_role_eq() { let admin = Role::Admin; let member = Role::Member; assert(admin == admin); assert(admin != member); assert(member == member); }
EXERCISE: Oh no! Why does Flux fail to verify that admin != member
in test_role_eq? Can you go back and figure out what bit of the above
to edit and fix, so that all the assert calls in test_role_eq are
verified by Flux.
Permissions Next, lets define the different kinds of permissions
that users may have to access resources. Again, we can use an enum
with a #[reflect] attribute.
#[reflect] #[derive(Clone, Copy, PartialEq, Eq, Hash)] pub enum Permissions { Read, Write, Comment, Delete, Configure }
Its rather tiresome to have to write out the full PartialEq
implementation, especially since we can automatically derive it using
Rust’s #[derive(PartialEq)]. However, now we are in a bit of a pickle.
When we explicitly wrote out the eq and ne methods above, we could
write an output type bool[r1 == r2] or bool[r1 != r2] respectively.
But now, we need a way to retroactively give Flux a specification for
the eq and ne methods. 1
Detached Specifications
Normally, Flux specifications are attached to the function or type or
trait using a Rust attribute like #[spec(...)] or #[reflect].
However, for situations like this, where you cannot modify the
original source because e.g. it is generated by a derive macro, or
perhaps because you’d rather just put the specifications elsewhere for
stylistic reasons, Flux also lets you write specifications that are
detached from their home in the source code. 2
#[specs { impl std::cmp::PartialEq for Permissions { #[reft] fn is_eq(p1: Permissions, p2: Permissions, v:bool) -> bool { v <=> (p1 == p2) } #[reft] fn is_ne(p1: Permissions, p2: Permissions, v:bool) -> bool { v <=> (p1 != p2) } fn eq(&Self[@r1], &Self[@r2]) -> bool[r1 == r2]; } }] const _: () = (); // just need something to attach the attribute to
The above “detached specification” says that we are providing
specifications for the PartialEq implementation for Permissions.
Flux will check these specifications against the (in this case, derived)
code, and will then let you use == and != on Permissions values.
fn test_eq_perms() { let read = Permissions::Read; let write = Permissions::Write; assert(read == read); assert(read != write); }
Refinement Level Functions
Now, that we’ve defined Roles and Permissions, we can define a
User struct that has their id and role, where we use a Flux index
to track the role of each User.
#[refined_by(role: Role)] pub struct User { pub name: String, #[field(Role[role])] pub role: Role, }
EXERCISE: Complete the specification and implementation of the
new method so that the code in test_user verifies.
impl User { // fill in the spec pub fn new(name: String, role: Role) -> Self { User { name, role } } #[spec(fn(&User[@u]) -> bool[u == Role::Admin])] pub fn is_admin(&self) -> bool { is_admin(&self.role) } #[spec(fn(&User[@u]) -> bool[u == Role::Guest])] pub fn is_guest(&self) -> bool { is_guest(&self.role) } } fn test_user() { let alice = User::new("Alice".to_string(), Role::Admin); let bob = User::new("Bob".to_string(), Role::Guest); assert(alice.is_admin()); assert(bob.is_guest()); }
Policies Lets restrict the set of Permissions that a User can
have based on their Role. For instance, suppose we want a policy where
-
Admins can do everything (i.e., have allPermissions), -
Members canRead,WriteandComment, but notDeleteorConfigure, -
Guests can onlyRead.
We can stipulate this policy in a refinement-level function
permitted that returns true exactly when a given Role is allowed
to have a given Permission.
defs! { fn permitted(r: Role, p: Permissions) -> bool { if r == Role::Admin { true } else if r == Role::Member { p != Permissions::Delete && p != Permissions::Configure } else { // Guest p == Permissions::Read } } }
Enforcement And now, we can use permitted to specify that only
users with the appropriate Role are allowed to perform certain
actions.
impl User { #[spec(fn(&Self[@u]) requires permitted(u.role, Permissions::Read))] fn read(&self) { /* ... */ } #[spec(fn(&Self[@u]) requires permitted(u.role, Permissions::Write))] fn write(&self) { /* ... */ } #[spec(fn(&Self[@u]) requires permitted(u.role, Permissions::Configure))] fn configure(&self) { /* ... */ } #[spec(fn(&Self[@u]) requires permitted(u.role, Permissions::Delete))] fn delete(&self) { /* ... */ } }
Flux will allow valid accesses,
fn test_access_ok() { let alice = User::new("Alice".to_string(), Role::Admin); alice.configure(); alice.delete(); }
but will swiftly reject, at compile-time, accesses that violate the policy:
fn test_access_bad() { let bob = User::new("Bob".to_string(), Role::Guest); bob.write(); // error! bob.delete(); // error! bob.configure(); // error! }
Summary
To recap, in this chapter we saw how to use
-
Reflect
enums, e.g. to refer to variants likeRole::Memberin refinements, -
Detached specifications for (derived) code e.g.
PartialEqimplementations, -
Refinement-level functions to specify contracts, e.g. policies on Roles,
which together, let us implement a simple role-based access control
system where Flux verifies that Users only access resources compatible
with their Role. Next, in this chapter we will see how to extend
our system with set-valued refinements that will allow for more
expressive access control.
-
From this chapter you may recall the notion of extern specifications; sadly we cannot quite use those because they are for things defined outside the current crate. ↩
-
Yes indeed, the code below is a lot of boilerplate, that is best generated by a macro, as we will see shortly, in this chapter. ↩
Dynamic Access Control
Previously, in this chapter we saw how to write a simple
role-based access control system, where each Role has a fixed set of
Permissions associated with it, and each User can only access the
resources that their Role allows. Next, lets see how to generalize
that to build a dynamic access control mechanism, where permissions
can be added or removed from users at runtime, while still ensuring
that they can only access resources allowed by their Role. To do so we
will use set-valued refinements to track the set of permissions that
each user currently has.
Roles & Permissions
Lets begin by recalling the whole business of roles and permissions.
Roles As before, we have three kinds of users: admins, members and
guests. This time, we will derive PartialEq and then use the
flux_core::eq! macro to generate the boilerplate detached
specifications needed to compare two Roles (described in
this chapter).
#[reflect] #[derive(Debug, Clone, PartialEq, Eq)] pub enum Role { Admin, Member, Guest, } flux_core::eq!(Role); use Role::*;
Permissions Next, lets define the different kinds of permissions
that users may have to access resources, using #[reflect] to let us
talk about Permissions in refinements, and the eq! macro to let us
compare them.
#[reflect] #[derive(Clone, Copy, PartialEq, Eq, Hash)] pub enum Permissions { Read, Write, Comment, Delete, Configure, } flux_core::eq!(Permissions); use Permissions::*;
Set-Valued Refinements
Instead of statically hardwiring a User‘s permissions to their Role,
our dynamic access control system will let us add or remove
permissions from a user at runtime. However, we will want to still
enforce important correctness requirements at compile time, and hence,
require a way to track the set of permissions a user has at any given
point.
Refined Sets To do so, we can use a refined Set library provided
by the flux-rs crate, which like the refined-vectors (described in
this chapter.md) are just a wrapper around Rust’s standard HashSet
but where we track the actual elements in the set via a set-valued
refinement index elems whose sort is Set<T>, where T is the type
of elements in the set. That is, just like we were tracking the
int-valued vector size in this chapter here we’re tracking the
Set<T>-valued elems.
#[opaque] #[refined_by(elems: Set<T>)] #[derive(Debug)] pub struct RSet<T> { pub inner: std::collections::HashSet<T>, }
Creating Sets The RSet API has a method to create an new set
(which is empty), and a method to add an element to a set, which
updates the set refinement to include the new elem element, using
the refinement level set_add operation.
#[trusted] impl<T> RSet<T> { #[spec(fn() -> RSet<T>[set_emp()])] pub fn new() -> RSet<T> { let inner = std::collections::HashSet::new(); RSet { inner } } #[spec(fn(self: &mut RSet<T>[@s], elem: T) ensures self: RSet<T>[set_add(elem, s)])] pub fn insert(self: &mut Self, elem: T) where T: Eq + Hash, { self.inner.insert(elem); } }
Membership Next, lets write a contains method to test if an
element is in an RSet.
impl<T> RSet<T> { #[spec(fn(set: &RSet<T>[@s], &T[@elem]) -> bool[set_is_in(elem, s.elems)])] pub fn contains(self: &Self, elem: &T) -> bool where T: Eq + Hash, { self.inner.contains(elem) } }
We can now check that are refinement-leve tracking is working as expected:
fn test_set_add() { let read = Permissions::Read; let write = Permissions::Write; let mut s = RSet::new(); s.insert(read); assert(s.contains(&read) && !s.contains(&write)); s.insert(write); assert(s.contains(&read) && s.contains(&write)); }
An rset! Macro Our API has enough mojo to implement a simple
rset! macro that will let us create RSets with a more convenient
syntax:
#[macro_export] macro_rules! rset { () => { RSet::new() }; ($($e:expr),+$(,)?) => {{ let mut res = RSet::new(); $( res.insert($e); )* res }}; }
We can kick the tires on the macro,
fn test_rset_macro() { let read = Permissions::Read; let write = Permissions::Write; let s = rset![read, write]; assert(s.contains(&read) && s.contains(&write)); }
Union & Intersection Next, it will be convenient to have operations
that compute the union and intersection, of two sets. We can
implement these using the corresponding operations on Rust’s HashSet:
#[trusted] impl<T : Eq + Hash + Clone> RSet<T> { #[spec(fn(&RSet<T>[@self], &RSet<T>[@other]) -> RSet<T>[set_intersection(self, other)])] pub fn intersection(&self, other: &RSet<T>) -> RSet<T> { let inner = self.inner.intersection(&other.inner).cloned().collect(); RSet { inner } } #[spec(fn(&RSet<T>[@self], &RSet<T>[@other]) -> RSet<T>[set_union(self, other)])] pub fn union(&self, other: &RSet<T>) -> RSet<T> { let inner = self.inner.union(&other.inner).cloned().collect(); RSet { inner } } }
Notice that for each method union, intersection, the output type is
indexed by the corresponding refinement-level operation on the input
sets. Lets test these out.
EXERCISE: Fix the conditions in the asserts below so they verify.
You may want to split them into multiple asserts to determine which
ones fail.
fn test_union_intersection() { let rd = Permissions::Read; let wr = Permissions::Write; let cm = Permissions::Comment; // make two sets let s1 = rset![rd, wr]; let s2 = rset![wr, cm]; // check union let su = s1.union(&s2); assert(!su.contains(&rd) && !su.contains(&wr) && !su.contains(&cm)); // check intersection let si = s1.intersection(&s2); assert(!si.contains(&rd) && !si.contains(&wr) && !si.contains(&cm)); }
Subset Finally, it will be useful to check if one set is a subset of another, that is, that all the elements of one set are also present in the other.
#[trusted] impl<T: Eq + Hash> RSet<T> { #[spec(fn(&RSet<T>[@self], &RSet<T>[@other]) -> bool[set_subset(self, other)])] pub fn subset(&self, other: &RSet<T>) -> bool { self.inner.is_subset(&other.inner) } }
We can now test some properties of union, intersection and subset,
for example, that the union of two sets contains both sets, and the
intersection is contained in both sets.
fn test_subset(s1: &RSet<Permissions>, s2: &RSet<Permissions>) { let su = s1.union(&s2); assert(s1.subset(&su) && s2.subset(&su)); let si = s1.intersection(&s2); assert(si.subset(&s1) && si.subset(&s2)); }
EXERCISE: Correct the implementation of the equals method so that
it verifies. Note that the == operator is legal for the Set<T> sort
inside refinements but it cannot be used in Rust code as we did not
define PartialEq for RSet<T>.
impl<T: Eq + Hash> RSet<T> { #[spec(fn(&RSet<T>[@self], &RSet<T>[@other]) -> bool[self == other])] pub fn equals(&self, other: &RSet<T>) -> bool { true // fix this } }
The Set of Permissions of Each Role
Lets use our refined RSet library to build a dynamic access control
system. As before, each Role has a fixed set of Permissions
associated with it. However, this time, we will specify these as a
refinement-level function (see
this chapter) that maps each Role to
the maximal set of Permissions for that role.
defs! { fn perms(r:Role) -> Set<Permissions> { if r == Role::Admin { set_add(Permissions::Read, set_add(Permissions::Write, set_add(Permissions::Delete, set_add(Permissions::Configure, set_emp())))) } else if r == Role::Member { set_add(Permissions::Read, set_add(Permissions::Write, set_add(Permissions::Comment, set_emp()))) } else { // Role::Guest set_add(Permissions::Read, set_emp()) } } }
A Slow Implementation The above permissions is a
refinement-level function that Flux refinements can use to specify
access control requirements. Fill in the method below that computes
the set of permissions valid for a Role.
impl Role { #[spec(fn(&Self[@r]) -> RSet<Permissions>[perms(r)])] pub fn permissions(&self) -> RSet<Permissions> { match self { Admin => rset!{}, // fill these in! Member => rset!{}, // fill these in! Guest => rset!{}, // fill these in! } } }
When you are done with the above, we can use it to implement a method
that checks if a given Permission is allowed for a Role.
#[spec(fn(&Self[@r], &Permissions[@p]) -> bool[set_is_in(p, perms(r))])] pub fn check_permission_slow(&self, p: &Permissions) -> bool { self.permissions().contains(p) }
A Fast Implementation The check_permission_slow method above is
correct, in that Flux proves that it returns true exactly if the given
permission is allowed for the role. However, it is inefficient since we
spin up a bunch of sets and membership queries to do the check.
EXERCISE: Complete the below implementation of an efficient (and correct) check using pattern-matching and equality comparisons.
#[spec(fn(&Self[@r], &Permissions[@p]) -> bool[set_is_in(p, perms(r))])] pub fn check_permission(&self, p: &Permissions) -> bool { let admin = Role::Admin; // use this let guest = Role::Guest; // use this let user = Role::Member; // use this match p { Permissions::Read => true, // fix this Permissions::Write => true, // fix this Permissions::Comment => true, // fix this Permissions::Delete => true, // fix this Permissions::Configure => true, // fix this } }
Users with Dynamic Permissions
The “dynamic” part of this access control system is that we want the
ability to add or remove permissions from a user at runtime, while
still ensuring that they can only access resources allowed by their
role. To do so, we will define a User struct that, in addition to a
role, will have two fields allowed and denied that will track the
set of permissions that have been added or removed from the user at
runtime.
#[derive(Debug)] struct User { name: String, role: Role, allow: RSet<Permissions>, deny: RSet<Permissions>, }
Allowed & Denied Permissions The allow and deny fields
respectively track the set of permissions that have been granted and
should never be granted to the User. Of course, we want these fields
to always satisfy some important invariants.
-
The
allowed permissions should always be a subset of the permissions associated with the user’srole. That is, we can only allow permissions that are valid for the user’s role; -
The
allowed permissions should never contain any permission that has already beendenied; that is, theallowed anddenyed sets should always be disjoint.
Enforcing Invariants
Lets use the detached specification mechanism — described in
this chapter — to enforce these invariants by refining
the struct to track the role and allow and deny sets as indices
and then specifying the requirements above as #[invariant]s on the
refined struct.
#[specs { #[refined_by(role:Role, allow:Set<Permissions>, deny:Set<Permissions>)] #[invariant(set_subset(allow, perms(role)))] #[invariant(set_intersection(allow, deny) == set_emp())] struct User { name: String, role: Role[role], allowed: RSet<Permissions>[allow], denied: RSet<Permissions>[deny], } }] const _: () = ();
The two #[invariant]s correspond directly to our requirements. Lets
check that Flux will only allow constructing legal Users that satisfy
these invariants.
EXERCISE: Can you fix the errors that Flux finds in alice and
bob?
fn test_user() { let alice = User { name: "Alice".to_string(), role: Guest, allow: rset!{ Read, Write }, deny: rset!{ }, }; let bob = User { name: "Bob".to_string(), role: Admin, allow: rset!{ Read, Write, Delete }, deny: rset!{ Write }, }; }
Dynamically Changing Permissions
Next, lets write methods to create new Users and check their
permissions:
impl User { #[spec(fn(name: String, role: Role) -> Self[User{role:role, allow: set_emp(), deny: set_emp()}])] fn new(name: String, role: Role) -> Self { Self { name, role, allow: RSet::new(), deny: RSet::new(), } } }
Allowing Permissions A newly created User only has a role but no
allowed or denyed Permissions, which ensures the invariants hold.
Lets write a method to add a Permission to the allowed set of a
User. Note that we must take care to ensure that the given
Permission is valid for the user’s role (to satisfy the first
invariant) and that it is not already in the denyed set (to satisfy
the second invariant). Thus, we make the method return true if the
permission was successfully added, and false otherwise.
impl User { #[spec(fn(me: &mut Self[@u], &Permissions[@p]) -> bool[allowed(u, p)] ensures me: Self[User{allow: add(u, p), ..u }])] fn allow(&mut self, p: &Permissions) -> bool { if self.role.check_permission(&p) && !self.deny.contains(&p) { self.allow.insert(*p); true } else { false } } }
In the type above, the refinement-level function allowed checks if a
permission can be added to the allowed set, and the add function
returns the extended permissions:
defs! { fn allowed(u: User, p: Permissions) -> bool { set_is_in(p, perms(u.role)) && !set_is_in(p, u.deny) } fn add(u: User, p: Permissions) -> Set<Permissions> { if allowed(u, p) { set_add(p, u.allow) } else { u.allow } } }
Notice that the type for the allow uses a strong reference described
in this chapter to conditionally
change the type of the User when we add permissions.
fn test_allow() { let read = Read; let write = Write; let mut guest = User::new("guest".to_string(), Role::Guest); assert(guest.allow(&read)); // can allow read assert(guest.allow.contains(&read)); // read is now allowed assert(!guest.allow(&write)); // cannot allow write assert(!guest.allow.contains(&read)); // write is not allowed }
Denying Permissions Next, lets write a similar method to deny a
permission, by adding it to the denyed set, (as long as it is not
already in the allowed set.
impl User { #[spec(fn(me: &mut Self[@u], &Permissions[@p]) -> bool[deny(u, p)] ensures me: Self[User { deny: del(u, p), ..u }])] fn deny(&mut self, p: &Permissions) -> bool { if !self.allow.contains(p) { self.deny.insert(*p); true } else { false } } }
EXERCISE: Correct the definitions of the deny and del
refinement-level functions so that the implementation of the deny
method above verifies.
defs! { fn deny(u: User, p: Permissions) -> bool { true // fix this } fn del(u: User, p: Permissions) -> Set<Permissions> { set_emp() // fix this } }
Access Control
Finally, we can use the allow set to control which Users are allowed
to perform certain actions. Unlike in our previous system
([ch]:11_equality), that used the User‘s fixed Role, we can now
use the dynamic allow set to make this determination.
impl User { #[spec(fn(&Self[@u]) requires set_is_in(Read, u.allow)))] fn read(&self) { /* ... */ } #[spec(fn(&Self[@u]) requires set_is_in(Write, u.allow)))] fn write(&self) { /* ... */ } #[spec(fn(&Self[@u]) requires set_is_in(Comment, u.allow)))] fn comment(&self) { /* ... */ } #[spec(fn(&Self[@u]) requires set_is_in(Delete, u.allow)))] fn delete(&self) { /* ... */ } #[spec(fn(&Self[@u]) requires set_is_in(Configure, u.allow)))] fn configure(&self) { /* ... */ } }
Flux checks that Users have the appropriate permissions to call these
methods.
fn test_access_ok() { let configure = Permissions::Configure; let alice = User::new("Alice".to_string(), Role::Admin); aliceconfigure(); // type error! alice.allow(&configure); // add it to the allowed set alice.configure(); // ok! }
Summary
In this chapter, we saw how to build a dynamic access control system, by indexing types with set-valued refinements that track users” permissions, and strong references which conditionally change types when we mutate references.
Dependent Typestates
Our next case study shows how Flux’s refinements can be used to make the
typestate even more expressive by connecting typestates with run-time
values to avoiding the blowup that ensues from using (only) Rust’s types
1 while still providing compile-time correctness guarantees. Lets
explore this idea by building a library to manipulate GPIO pins on
embedded hardware where each port comprises multiple pins each of
which can be set to be in Input or Output mode, and must be used
according to its current mode.
Bitvectors
The pins” modes will be configured and accessed via bitwise operations
on dedicated hardware registers. Flux lets us precisely track the
results of bitwise operations — just like we can track arithmetic
operations ([ch]:02_refinements) or set operations ([ch]:12_sets) —
with a special flux_rs::bitvec::BV32 type that represents 32-bit
bitvectors as an opaque (see this chapter.md) newtype wrapper around
u32 indexed by a bitvec<32> that tracks the bits of the underlying
u32 2.
#![allow(unused)] fn main() { #[refined_by(x: bitvec<32>)] // bitvector-valued index pub struct BV32(u32); }
Creating and Operating on Bitvectors
The API for BV32 has methods to convert from and to u32 whose refine
contracts use the logical functions bv_int_to_bv32 and
bv_bv32_to_int to convert between the int index (of the u32) and
its bitvec<32> representation (of the BV32).
impl BV32 {
#[spec(fn(value: u32) -> BV32[bv_int_to_bv32(value)])]
pub fn new(value: u32) -> BV32 { BV32(value) }
}
impl Into<u32> for BV32 {
#[spec(fn(self:BV32) -> u32[bv_bv32_to_int(self)])]
pub fn into(self) -> u32 { self.0 }
}
Bitvector Operations The flux_rs::bitvec library implements the
various traits like BitAnd, BitOr, Not, Shl, Shr, etc. to
enable bitwise operations on BV32 values. For example, the
left-shift (<<) operation is implemented as
#![allow(unused)] fn main() { impl Shl<u32> for BV32 { #[spec(fn(self, rhs: u32) -> BV32[self << bv_int_to_bv32(rhs)])] fn shl(self, rhs: u32) -> BV32 { BV32(self.0 << rhs) } } }
and the bitwise or (|) operation is implemented as
#![allow(unused)] fn main() { impl BitOr for BV32 { #[spec(fn(self, rhs: BV32) -> BV32[self | rhs])] fn bitor(self, rhs: BV32) -> BV32 { BV32(self.0 | rhs.0) } } }
EXERCISE: Lets test our operators out: can you fix the code below so
the assert is verified by Flux?
#[spec(fn () -> u32[10])] fn test_shl_or() { let b1 = BV32::new(1); // 0b0001 let b5 = BV32::new(5); // 0b0101 let res = b5 << b1; // 0b1010 let res = res | b1; // 0b1011 res.into() }
Getting and Setting Individual Bits
Next, lets use the bitwise operations to write functions that get or
set a bit at a particular position in a BV32.
Valid Bit Positions Lets first write an alias for valid bit
positions (0 to 31)
#[alias(type Pin = u8{n: 0 <= n && n < 32})] type Pin = u8;
Note that while rustc will allow any u8 value to be used as a Pin,
Flux will complain if we try to use a value outside the valid range.
Getting the Value of a Pin We can now write a function that gets
the value of a BV32 at a given position by returning true if the bit
is set to 1 and false otherwise.
fn get_pin(bv: BV32, pin: Pin) -> bool { ((bv >> pin) & 1) == b1 }
Setting the Value of a Pin Similarly, we can write a function that
takes as input a bool and sets the bit at the given position to 1
if the bool is true and to 0 otherwise.
fn set_pin(bv:BV32, pin:Pin, b:bool) -> BV32 { if b { bv | (BV32::new(1) << pin) } else { bv & !(BV32::new(1) << pin) } }
Refinement-Level Get/Set Functions To verify code that uses
get_pin and set_pin, we need to specify their behavior using Flux
contracts. The most direct way to do so is to write refinement
functions (see this chapter) like get_pin,
defined below
defs! { fn get_pin(bv: bitvec<32>, pin: int) -> bool{ let val = (bv >> bv_int_to_bv32(pin)) & 1; val == 1 } }
and set_pin which is similarly defined as shown below
defs! { fn set_pin(bv: bitvec<32>, pin: int, val: bool) -> bitvec<32> { let index_bits = bv_int_to_bv32(pin); if val { bv | (1 << index_bits) } else { bv & bv_not(1 << index_bits) } } }
Syntax: While we have tried to make the syntax of the refinement
function set_pin shown above look like the implementation of the
Rust method of the same name, they are not the same thing. Indeed,
notice we wrote bv_not instead of ! in the refinement function as
! is reserved for boolean negation inside refinement expressions.
Connecting Rust Methods with Refinement Functions Once we have defined the refinement functions, we can use them to specify the output types of the corresponding Rust functions, using detached specifications (see this chapter).
detached_spec! { fn get_pin(bv: BV32, pin: Pin) -> bool[get_pin(bv, pin)]; fn set_pin(bv: BV32, pin: Pin, b: bool) -> BV32[set_pin(bv, pin, b)]; }
We can confirm that the specifications for the above are correctly tracking the bits via the following test:
fn test_get_set_pin() { let b5 = BV32::new(5); // 0b0101 flux_rs::assert(get_pin(b5, 2)); // bit 2 is set let b5 = set_pin(b5, 2, false); // 0b0001 flux_rs::assert(!get_pin(b5, 2)); // bit 2 is cleared }
GPIO Ports
Lets tuck the newly learned information about bitvectors into our pockets and now turn to the issue at hand: developing an API for interacting with General Purpose Input/Output (GPIO) ports in low-level embedded microcontrollers.
Ports and Pins GPIO ports are the conduit through which
microcontrollers “talk” to the external world, e.g. to read sensors
that determine key-presses or light up output LEDs. GPIO ports, are
themselves collections of pins that can be configured individually as
either Input or Output, and which can then be read from or written
to accordingly. The developer must take care to use each pin according
to how it’s mode was configured, as otherwise the hardware may produce
invalid data or worse, may destroy the hardware by releasing its “magic
smoke” 3!
Registers In common hardware platforms like the STM32, ports are controlled via dedicated memory mapped port registers which control the modes and input and output values of all the pins in that port, where the ith bit in the register corresponds to the ith pin of the port. We can model such registers in Rust as
#[repr(C)] struct Registers { modes: BV32, // Bit 0 = pin 0 mode, bit 1 = pin 1 mode, etc. output: u32, // Bit 0 = pin 0 output, bit 1 = pin 1 output, etc. input: u32, // Bit 0 = pin 0 input, bit 1 = pin 1 input, etc. }
and then the GPIO port itself is a wrapper around a pointer to such registers
struct Gpio(*mut Registers);
Tracking Modes
If you are well-caffeinated, you may have noticed that we used the
BV32 type for the modes register in Registers struct above, as it
will let us index the struct Registers with a bitvec<32> that tracks
the modes of all 32 pins in the GPIO port.
detached_spec! { #[refined_by(modes: bitvec<32>)] struct Registers { modes: BV32[modes], output: u32, input: u32, } }
Similarly, lets refine struct Gpio to track the modes of the
Registers that it points to
#[refined_by(modes: bitvec<32>)] #[opaque] struct Gpio; }
Private Trusted API As the actual Registers must be accessed
directly via unsafe pointer dereferences, we mark the struct as
opaque (see this chapter.md) and write a small suite of private
trusted (i.e. unverified) methods for the unsafe dereferences,
that we will then use to to build a verified public API for port
access.
#[trusted] impl Gpio { #[spec(fn(&Gpio[@modes]) -> &Registers[modes])] fn get_registers(&self) -> &Registers { unsafe { &*self.0 } } #[spec(fn(self: &mut Gpio, m: BV32) ensures self: Gpio[m])] fn set_modes(&mut self, m: BV32) { unsafe { (&mut *self.0).modes = m} } #[spec(fn(self:&mut Gpio[@m], output:u32) ensures self: Gpio[m])] fn set_output(&mut self, output: u32) { unsafe { (&mut *self.0).output = output } } }
The get_registers dereferences the pointer stashed inside the Gpio
to return a Registers that has exactly the same modes. Dually, the
set_modes updates the modes of the underlying Registers with the
given value, updating the refinement of the Gpio accordingly. Finally,
the set_output updates the output register pointed to by the Gpio
but leaves the modes unchanged.
Peripherals Finally, we can bundle multiple GPIO ports into a
Peripherals struct that represents all the hardware peripherals of a
microcontroller.
struct Peripherals { gpio_a: Gpio, gpio_b: Gpio, gpio_c: Gpio }
We can then provide safe singleton access to the peripherals via a
take_peripherals function that maps the actual addresses of the
hardware registers to Gpio instances.
#[trusted] fn take_peripherals() -> Option<Peripherals> { static TAKEN: AtomicBool = AtomicBool::new(false); if TAKEN .compare_exchange(false, true, Ordering::SeqCst, Ordering::SeqCst) .is_ok() { Some(Peripherals { gpio_a: Gpio(0x4800_0000 as *mut Registers), gpio_b: Gpio(0x4800_0400 as *mut Registers), gpio_c: Gpio(0x4800_0800 as *mut Registers), }) } else { None } }
Using Modes
Next, lets use the private methods to implement a public API for GPIO
access that gets and sets a pin’s modes, and ensures it is used
according to its mode. First, lets write an enum to represent the
modes of a Pin
#[reflect] #[derive(PartialEq, Eq)] enum Mode { Input, Output } flux_core::eq!(Mode);
We could have just used bool but sadly, I kept mixing up whether
true meant Input or Output. An enum rather dispels the
confusion! However it will be quite convenient to convert between Mode
and bool with two helper functions
impl From<bool> for Mode { #[spec(fn (b: bool) -> Mode[bool_to_mode(b)])] fn from(b: bool) -> Self { if b { Mode::Output } else { Mode::Input } } } impl Into<bool> for Mode { #[spec(fn (mode: Mode) -> bool[mode_to_bool(mode)])] fn into(self) -> bool { match self { Mode::Output => true, Mode::Input => false, } } }
whose specifications use the refinement functions
defs! { fn bool_to_mode(b:bool) -> Mode { if b { Mode::Output } else { Mode::Input } } fn mode_to_bool(mode: Mode) -> bool { mode == Mode::Output } }
Getting the Mode Lets use the private API and the bitvector helpers
to implement a public method to get a Pin‘s mode, using get_pin
defined earlier plus the Mode-bool conversion.
impl Gpio { #[spec(fn(&Gpio[@modes], pin: Pin) -> Mode[get_mode(modes, pin)])] pub fn get_mode(&self, pin: Pin) -> Mode { Mode::from(get_pin(self.get_registers().modes, pin)) } }
where the specification function get_mode is just
defs! { fn get_mode(bv: bitvec<32>, index: int) -> Mode { bool_to_mode(get_pin(bv, index)) } }
Setting the Mode Similarly, we can implement a public method to set
a Pin‘s mode using set_pin defined earlier plus the Mode-bool
conversion.
impl Gpio { // #[spec(EXERCISE)] pub fn set_mode(&mut self, pin: Pin, mode: Mode) { let regs = self.get_registers(); self.set_modes(set_pin(regs.modes, pin, mode.into())) } }
EXERCISE: Write the specification for set_mode so Flux verifies
test_get_set.
#[spec(fn(gpio: &mut Gpio[@modes]) ensures gpio: Gpio[modes])] fn test_get_set(gpio: &mut Gpio) { let orig = gpio.get_mode(3); // save original mode gpio.set_mode(3, Mode::Output); // set to output assert(gpio.get_mode(3) == Mode::Output); // verify mode gpio.set_mode(3, orig); // restore original mode }
Input and Output Pins We want the methods that read from and write
to a Pin to only be invoked on pins that are configured to be in
Input or Output mode respectively. First, lets write a type alias
for such pins (as always, paired with a matching Rust-level alias that
can be used in Rust signatures.)
#[alias(type In(m:bitvec<32>) = Pin{v:get_mode(m, v) == Mode::Input})] type In = Pin; #[alias(type Out(m:bitvec<32>) = Pin{v:get_mode(m, v) == Mode::Output})] type Out = Pin;
Dependent Aliases: Unlike the definition of Pin which is simply a
u8 between 0 and 32, the definitions of the aliases In and Out
depend on the bitvec<32> index m. This is essential as actual
mode is stored in the modes register and not the Pin itself. Flux
supports such dependent aliases with alias parameters like
m: bitvec<32> that can be used in the alias body, and which must then
be supplied wherever the aliases are used in Flux specifications.
Reading & Writing Pins Finally, lets use the alias to write read
and write methods that only accept In and Out pins, respectively
impl Gpio { #[spec(fn(&Gpio[@modes], pin: In(modes)) -> bool)] pub fn read(&self, pin: In) -> bool { let regs = self.get_registers(); get_pin(regs.input.into(), pin) } #[spec(fn(self: &mut Gpio[@modes], pin: Out(modes), value: bool))] pub fn write(&mut self, pin: Out, value: bool) { let output = self.get_registers().output.into(); let new_output = set_pin(output, pin, value).into();; self.set_output(new_output); } }
Well then, we now have a complete API to determine and configure the modes of each pin, and read and write them according to their enabled modes, such that that Flux can statically ensure that the “magic smoke” stays inside!
Clients
Lets test our API out with some example client code.
Reading and Writing Pins Here’s an example that illustrates how we
can use our GPIO API to configure and access different pins on different
ports. First, we get mutable access to the GPIO ports via the
take_peripherals function. Next, we configure some pins as Output
and others as Input. Flux will use the specification for set_mode to
track each of the pins” modes separately (in the modes index for
gpio_a and gpio_b). Consequently, Flux will allow us to read from
the Input pins, and write to the Input pins. However, Flux will
prevent you from trying to read from or write to an Output or
Input pin, respectively, as you can see by uncommenting the lines at
the bottom of the function.
fn test_read_write() { // Get mutable access to GPIOA let mut peripherals = take_peripherals().expect("taken!"); let gpio_a = &mut peripherals.gpio_a; let gpio_b = &mut peripherals.gpio_b; // Different pins, different states gpio_a.set_mode(0, Mode::Output); // PA0 : Out gpio_a.set_mode(1, Mode::Output); // PA1 : Out gpio_a.set_mode(5, Mode::Input); // PA5 : In gpio_b.set_mode(0, Mode::Input); // PB3 = In // Valid accesses gpio_a.write(0, true); gpio_a.write(1, true); let button_state = gpio_a.read(5); let timer_state = gpio_b.read(0); // Invalid accesses caught at compile-time // gpio_a.read(0); // ERROR! Can't read from Out pin // gpio_a.write(5, true); // ERROR! Can't write to In pin }
Reading Multiple Pins Your turn! Consider the function below that
takes as input sequence of Pins, and returns as output a vector of the
bool obtained from reading the sequence of Pins.
EXERCISE: Write a spec that lets Flux verify read_pins.
fn read_pins(gpio: &Gpio, pins: &[Pin]) -> Vec<bool> { let mut res = vec![]; for pin in pins { res.push(gpio.read(*pin)); } res }
Writing Multiple Pins And here is a similar function that
additionally takes as input a sequence of bool values to write to the
corresponding sequence of Pins.
EXERCISE: Write a spec that lets Flux verify write_pins.
fn write_pins(gpio: &mut Gpio, pins: &[Pin], vals: &[bool]) { for i in 0..pins.len() { gpio.write(pins[i], vals[i]); } }
Dynamic Mode Configuration Lets look at an example where we might
want to “force” a Pin to Output mode, optionally returning its value
if it was (previously) in Input mode. Flux will not let us read from a
pin until we have established that the current mode (obtained by
get_mode) is, in fact, Input. At that point, we can read the pin,
and then set it to Output mode.
#[spec(fn(gpio: &mut Gpio, pin:Pin) -> Option<bool> ensures gpio: Gpio)] fn detect_and_set(gpio: &mut Gpio, pin: Pin) -> Option<bool> { // gpio.read(pin); // ERROR can't read, don't know state! if let Mode::Input = gpio.get_mode(pin) { let val = gpio.read(pin); gpio.set_mode(pin, Mode::Output); return Some(val); } None }
Blinking a Status LED One often wants an embedded device to blink, e.g. to let us know its alive and kicking. The usual maneuver is to toggle a dedicated status LED pin inside the main loop of the application.
EXERCISE: Fix the spec so Flux verifies blink_status_led.
#[spec(fn(gpio: &mut { Gpio[@modes] | true}))] fn blink_status_led(gpio: &mut Gpio) { static mut LED_STATE: bool = true; let value = unsafe { LED_STATE = !LED_STATE; LED_STATE }; gpio.write(13, value); // HINT: When is this ok to call? }
EXERCISE: Here’s the main “loop” of an embedded application that
blinks the status LED to indicate the system is alive. Can you find out
why Flux rejects the call to blink_status_led, and remedy mattes so
that app is accepted?
fn app() { let mut peripherals = take_peripherals().expect("taken!"); let gpio_c = &mut peripherals.gpio_c; // blink_status_led(gpio_c); // ERROR! not yet Output detect_and_set(gpio_c, 13); // ensure pin 13 is Output loop { // let result = process_data(read_sensors()); // update_outputs(result); blink_status_led(gpio_c); // indicate system is alive } }
Summary
In this chapter, we learned about Flux’s support for bitvector valued
refinements via the BV type, and how to use bitvectors to track the
modes of GPIO pins, to write a verified GPIO library that ensures pins
are used per their configuration.
Existing embedded Rust libraries track pin modes in Rust’s using
PhantomData and the typestate pattern 4. While this approach has
the advantage of working out of the box with plain rustc, it has two
drawbacks. First, we get a explosion in the number of types, and the
attendant duplication of methods. Second, and perhaps more
importantantly, we end up tracking the state of the Pin at the
type-level, when we really want to track state of the modes register
to avoid any shenanigans that might arise concurrently accessing
different pins of the same port. (The classic typestate approach would
end up having to create 232 different types to track all mode
configurations of a single port!)
In contrast, Flux’s refinements allow us to compactly track the entire vector of modes via logical refinements while still providing compile-time guarantees that each pin is used according to its configured mode.
-
Flux also supports
BV8,BV16andBV64types for 8-, 16- and 64-bit bitvectors, but lets focus onBV32for simplicity ↩ -
https://docs.rust-embedded.org/book/static-guarantees/state-machines.html ↩
Neural Networks
Next, lets look at a case study that ties together many of the different features of Flux that we have seen in the previous chapters: lets build a small neural network library. This chapter is heavily inspired by this blog post 1 and Michael Nielsen’s book on neural networks 2.
 |  |
A Neural Network Layer with 3 inputs and 4 outputs.
Layers
Per wikipedia, a neural network 3 “consists of connected units or nodes called artificial neurons … Each artificial neuron receives signals from connected neurons, then processes them and sends a signal to other connected neurons… The output of each neuron is computed by some non-linear (activation) function of the totality of its inputs… The strength of the signal at each connection is determined by a weight… Typically neurons are aggregated into layers…”
Figure [fig]:neural-layer illustrates, on the left, a single neural
network layer with 3 inputs and 4 outputs. Each output neuron
receives a signal from each of the 3 input neurons, as shown by the
edges from the inputs to the outputs. Furthermore, as shown on the
right, each edge has a weight. For example, the ith
output neuron has distinct weights weight[i][0] and weight[i][1] and
weight[i][2] for each of its input neurons.
Representing Layers We can represent a layer as a struct with
fields for the number of inputs, outputs, weights, and biases.
struct Layer { num_inputs: usize, num_outputs: usize, weight: RVec<RVec<f64>>, bias: RVec<f64>, outputs: RVec<f64>, }
Of course, the plain Rust definition says little about the Layer‘s
dimensions. That is it does not tell us that weight is a 2D vector
that stores for each of the num_outputs, a vector of size
num_inputs, and that bias and outputs are vectors of length
num_outputs. No matter! We refine the Layer struct with a detached
4 specification that makes these relationships explicit.
#[specs { #[refined_by(i: int, o: int)] struct Layer { num_inputs: usize[i], num_outputs: usize[o], weight: RVec<RVec<f64>[i]>[o], bias: RVec<f64>[o], outputs: RVec<f64>[o], } }] const _: () = ();
Lets step through the detached specification.
-
First, we declare that the
Layerstruct is refined by twointindexesiando, which will represent the input and output dimension of theLayer; -
Next, we refine the
num_inputsfield asusize[i]andnum_outputsfield to be of typeusize[o], meaning that its value is equal to the indexiandorespectively, and hence, that those fields represent the run-time values of their respective dimensions. -
Next, we refine the
weightfield to be a refined vector 5 of vectorsRVec<RVec<f64>[i]>[o]indicating that for each of theooutputs, we have a vector ofiweights, one for each input; -
Finally, we refine the
biasandoutputsfields to be vectors of lengtho, indicating a single bias and output value for each output neuron.
Why Detach? We could just as easily have written the above as a
regular attached specification, using attributes on the fields of the
Layer struct. We chose to use the detached style here purely for
illustration, and because I personally think its somewhat easier on the
eye.
Creating Layers
Next, lets write a constructor for Layers.
Initializing a Vector Since we have to build nested vectors, it will be convenient to write a helper function that uses a closure to build a vector of some given size.
#[spec(fn(n: usize, f:F) -> RVec<A>[n] where F: FnMut(usize) -> A)] fn init<F, A>(n: usize, mut f: F) -> RVec<A> where F: FnMut(usize) -> A, { let mut res = RVec::new(); for i in 0..n { res.push(f(i)); } res }
EXERCISE: The function below takes as input a reference to a RVec
and uses init to compute the mirror image of the input, i.e., an
RVec where the elements are reversed. Can you fix the specification of
init so it is accepted?
#[spec(fn(vec: &RVec<T>[@n]) -> RVec<T>[n])] fn mirror<T: Clone>(vec: &RVec<T>) -> RVec<T> { let n = vec.len(); init(n, |i| vec[n-i-1].clone()) }
Layer Constructor Our Layer constructor will use init to create
a randomly generated starting matrix of weights and biases that will
then get adjusted during training. Hooray for closures: we can call
init with an outer closure that creates each output row of the
weight matrix, and an inner closure that creates the input weights for
that row.
impl Layer { #[spec(fn(i: usize, o: usize) -> Layer[i, o])] fn new(i: usize, o: usize) -> Layer { let mut rng = rand::thread_rng(); Layer { num_inputs: i, num_outputs: o, weight: init(i, |_| init(o, |_| rng.gen_range(-1.0..1.0))), bias: init(o, |_| rng.gen_range(-1.0..1.0)), outputs: init(o, |_| 0.0), } } }
EXERCISE: Looks like the auto-complete snuck in a bug in definition
of new above, which, thankfully, Flux has flagged! Can you spot and
fix the problem?
Layer Propagation
A neural layer (and ultimately, network) is, of course, ultimately a representation of a function that maps inputs to outputs, for example, to map inputs corresponding to the pixels of an image to outputs corresponding to the labels of objects in the image. Thus, each neural layer must implement two key functions:
-
forwardwhich evaluates the function by computing the values of the outputs given the current values of the inputs, weights, and biases; and -
backwardwhich propagates the error (or loss) between the evaluated output backwards by computing the gradients of the weights and biases with respect to the loss, and then “trains” the network by adjusting the weights and biases to minimize the loss.
Next, let’s look at how we might implement these function using our
Layer datatype. We will not look at the mathematics of these functions
in any detail, to learn more, I heartily recommend chapters 2 and 3 of
Nielsen’s book 6.
Forward Evaluation
In brief, the goal of the forward function is to compute the value of
each output neuron outputs[i] as the weighted sum of its input
neurons inputs[i], and return 1 if that sum plus its bias[i] — a
threshold — is above zero, and 0 otherwise.
\[ \mathbf{\text{outputs}}\lbrack i\rbrack ≔ \begin{cases} 1\text{ if }\mathbf{\text{weights}}\lbrack i\rbrack \cdot \mathbf{\text{inputs}} + \mathbf{\text{bias}}\lbrack i\rbrack > 0 \\ 0\text{ otherwise } \end{cases} \]
The discrete “step” function above discontinuously leaps from 0 to 1
at the threshold, which gets in the way of computing gradients during
backpropagation. So instead we smooth it out using a sigmoid
(logistic) function
\[
\sigma(x) ≔ \frac{1}{1 + \exp( - x)}
\]
which transitions gradually from 0 to 1 as shown below:

Sigmoid vs. Step Function
Thus, when we put the weighted-sum and sigmoid together, we get the following formula for computing the ith output neuron:
\[ \mathbf{\text{outputs}}\lbrack i\rbrack ≔ \sigma(\mathbf{\text{weights}}\lbrack i\rbrack \cdot \mathbf{\text{inputs}} + \mathbf{\text{bias}}\lbrack i\rbrack) \]
EXERCISE: Below is the implementation of a function that computes
the dot_product of two vectors. Can you figure out why Flux is
complaining and fix the code so it verifies?
fn dot_product2(a: &RVec<f64>, b: &RVec<f64>) -> f64 { (0..a.len()).map(|i| (a[i] * b[i])).sum() }
We can now use the implementation of dot_product to transcribe the
equation above math into our Rust implementation of forward
impl Layer { #[spec(fn(&mut Layer[@l], &RVec<f64>) )] fn forward(&mut self, input: &RVec<f64>) { (0..self.num_outputs).for_each(|i| { let weighted_input = dot_product(&self.weight[i], input); self.outputs[i] = sigmoid(weighted_input + self.bias[i]) }) } }
EXERCISE: Flux is unhappy about the implementation of forward. Can
you figure out why and add the type specification that lets Flux verify
the code?
Backward Propagation
Next, lets implement the backward propagation function that takes as
input the inputs given to the Layer and the error produced by a
given Layer (roughly, the difference between the expected output and the
actual output of that layer), and learning rate hyper-parameter that
controls the step size for gradient descent, to
-
Update the weights and biases of the layer to reduce the error, and
-
Propagate the appropriate amount of error to the previous layer.
impl Layer { fn backward(&mut self, inputs: &RVec<f64>, err: &RVec<f64>, rate:f64) -> RVec<f64> { let mut input_err = rvec![0.0; inputs.len()]; for i in 0..self.num_outputs { for j in 0..self.num_inputs { input_err[j] += self.weight[i][j] * err[i]; self.weight[i][j] -= rate * err[i] * inputs[j]; } self.bias[i] -= rate * err[i]; } input_err } }
The code works as follows.
-
First, we initialize the
input_errvector that corresponds to theerrpropagated backwards (to the previous layer); -
Next, we loop over each output neuron
i, and iterate over each of its inputsjto accumulate that input’s weighted contribution to theerr, and updateweight[i][j](and similarly,bias[i]) with the gradienterr[i] * inputs[j]multiplied by theratewhich ensures we subsequently reduce the error;
EXERCISE: Looks like we forgot to write down the appropriate
dimensions for the input Layer and the various input and output
vectors, which makes Flux report errors all over the place. Can you fill
them in so the code verifies?
Composing Layers into Networks
A neural network is the composition of multiple layers.
[fig]:neural-network shows a network that maps 3-inputs to 4-outputs,
with three hidden levels in between which respectively 4, 2, and 3
neurons. Put another way, we might say that the network in the figure
composes four Layers shown in blue, green, yellow and orange
respectively. In this case, the Layers match up nicely, with the
outputs of each precisely matching the inputs of the next layer. Next,
lets see how Flux can help ensure that we only ever construct networks
where the layers snap together perfectly.

A 3-input, 4-output neural network with three hidden levels.
The key idea is to think of building up the network from the right to the left, starting with the final output layer, and working our way backwards.
-
The last orange
Layer[3, 4]corresponds to aNetworkthat maps 3 inputs to 4 outputs (lets call that aNetwork[3, 4]); -
Next, we add the yellow
Layer[2, 3]that composes with theNetwork[3, 4]to give us aNetwork[2, 4]; -
Next, we slap on the green
Layer[4, 2]which connects with theNetwork[2, 3]to give aNetwork[4, 4]; -
Finally, we top it off with the blue
Layer[3, 4]that connects with theNetwork[4, 4]to give us the finalNetwork[3, 4].
Refined Networks Lets codify the above intuition by defining a
recursive Network that is refined by the number of input and output
neurons.
enum Network { #[variant((Layer[@i, @o]) -> Network[i, o])] Last(Layer), #[variant((Layer[@i, @h], Box<Network[h, @o]>) -> Network[i, o])] Next(Layer, Box<Network>), }
Lets consider the two variants of the Network enum.
-
The
Lastvariant takes as input aLayer[i, o]to construct aNetwork[i, o], just like the orangeLayer[3, 4]yields aNetwork[3, 4]; -
The
Nextvariant takes as input aLayer[i, h]which mapsiinputs tohhidden neurons, and aNetwork[h, o]which maps thosehhidden neurons toooutputs, to construct aNetwork[i, o]that mapsiinputs toooutputs!
The network in [fig]:neural-network can thus be represented as
#[spec(fn() -> Network[3, 4])] fn example_network() -> Network { let blue = Layer::new(3, 4); let green = Layer::new(4, 2); let yellow = Layer::new(2, 3); let orange = Layer::new(3, 4); network![blue, green, yellow, orange] }
where the network! macro recursively applies Next and Last to
build the Network.
#[macro_export] macro_rules! network { ($last:expr) => { Network::Last($last) }; ($first:expr, $($rest:expr),+) => { Network::Next($first, Box::new(network!($($rest),+))) }; }
EXERCISE: Complete the specification and implementation of a
function Network::new that takes as input the number of inputs, a
slice of hiddens, and the number of outputs and returns a Network
that maps the inputs to outputs after passing through the specified
hidden layers.
impl Network { fn new(inputs: usize, hiddens: &[usize], outputs: usize) -> Network { if hidden_sizes.is_empty() { Network::Last(Layer::new(input_size, output_size)) } else { todo!() } } }
When done, the following should create a Network like that in
[fig]:neural-network.
#[spec(fn() -> Network[3, 4])] fn test_network() -> Network { Network::new(3, &[4, 2, 3], 4) }
Network Propagation
Finally, lets implement the forward and backward functions so that
they work over the entire Network, thereby allowing us to do both
training and inference.
Forward Evaluation
EXERCISE: The forward evaluation recurses on the Network,
calling forward on each Layer and passing the outputs to the next
part of the Network, returning the output of the Last layer. Fill in
the specification for forward so it verifies.
fn forward(&mut self, input: &RVec<f64>) -> RVec<f64> { match self { Network::Next(layer, next) => { layer.forward(input); next.forward(&layer.outputs) } Network::Last(layer) => { layer.forward(input); layer.outputs.clone() } } }
Back Propagation
The back-propagation function assumes we have already done a forward
pass, and have the outputs stored in each Layer‘s outputs field. It
then takes as input the target or expected output, computes the
error at the last layer, and then propagates that error backwards
through the network, updating the weights and biases as it goes using
the gradients computed at each layer via its backward function.
fn backward(&mut self, inputs:&RVec<f64>, target:&RVec<f64>, rate:f64) -> RVec<f64> { match self { Network::Last(layer) => { let err = (0..layer.num_outputs) .map(|i| layer.outputs[i] - target[i]) .collect(); layer.backward(inputs, &err, rate) } Network::Next(layer, next) => { todo!("exercise: fill this in") } } }
EXERCISE: Complete the specification and implementation of
backward above so that it recursively propagates the error all the way
to the first layer, by calling backward on each of the intermediate
layers.
Summary
To recap, in this chapter, we saw how to build a small neural network
library from scratch in Rust, using Flux’s refinement types to track the
dimensions of each network Layer and to ensure that they are composed
correctly into a Network. Note that doing so requires checking a
“linking” property: that the outputs of one layer match the inputs of
the next layer, and that this happens for an unbounded number of layers.
Its rather convenient that one can neatly tuck this invariant inside the
enum definition of Network, in a way that the type checker can then
verify automatically at compile time!
-
https://byteblog.medium.com/building-a-simple-neural-network-from-scratch-in-rust-3a7b12ed30a9 ↩
-
https://en.wikipedia.org/wiki/Neural_network_(machine_learning) ↩
-
As described in this chapter ↩
-
As described in this chapter ↩
Flux Specifications
One day, this will be an actual user's guide, but for now,
it is a WIP guide to writing specifications in flux, as
illustrated by examples from the regression tests.
Refinement Types
-
Indexed Type: An indexed type
B[r]is composed of a base Rust typeBand a refinement indexr. The meaning of the index depends on the type. Some examples arei32[n]: denotes the (singleton) set ofi32values equal ton.List<T>[n]: values of typeList<T>of lengthn.
-
Refinement parameter: Function signatures can be parametric on refinement variables. Refinement parameters are declared using the
@nsyntax. For example, the following signature:fn(i32[@n]) -> i32[n + 1]binds
nover the entire scope of the function to specify that it takes ani32equal tonand returns ani32equal ton + 1. This is analogous to languages like Haskell where a lower case letter can be used to quantify over a type, e.g., the typea -> ain Haskell is polymorphic on the typeawhich is bound for the scope of the entire function type. -
Existential Type: An existential type
B{v: r(v)}is composed of a base typeB, a refinement variablevand a refinement predicateronv. Intuitively, a Rust valuexhas typeB{v: r(v)}if there exists a refinement valueasuch thatr(a)holds andxhas typeB[a].i32{v: v > 0}: set of positivei32values.List<T>{v: v > 0}: set of non-empty lists.
-
Constraint Type: A constraint type has the form
{T | r}whereTis any type (not just a base type). Intuitively, a value has type{T | r}if it has typeTand alsorholds. They can be used to constraint a refinement parameter. For example, the following signature constraint the refinement parameternto be less than10.fn({i32[@n] | n < 10}) -> i32[n + 1]Constraint types serve a similar role as existentials as they can also be used to constraint some refinement value with a predicate, but an existential type can only be used to constraint refinement variable that it bound locally, in contrast constraint types can be used to constraint a "non-local" parameter. This can be seen in the example above where the parameter
ncannot be bound locally because it has to be used in the return type.
Argument Syntax
The @n syntax used to declare refinements parameters can be hard to read sometimes. Flux also supports a syntax that let you bind refinement parameters using colons similar to the syntax used to declare arguments in a function. We call this argument syntax. This syntax desugars to one of the refinements forms discussed above. For example, the following signature
fn(x: i32, y: i32) -> i32[x + y]
desugars to
fn(i32[@x], i32[@y]) -> i32[x + y]
It is also possible to attach some constraint to the parameters when using argument syntax. For example,
to specify that y must be greater than x using argument syntax we can write:
fn(x: i32, y: i32{x > y}) -> i32[x + y]
This will desugar to:
fn(i32[@x], {i32[@y] | x > y}) -> i32[x + y]
Grammar of Refinements
The grammar of refinements (expressions that can appear as an index or constraint) is as follows:
r ::= n // numbers 1,2,3...
| x // identifiers x,y,z...
| x.f // index-field access
| r + r // addition
| r - r // subtraction
| n * e // multiplication by constant
| if r { r } else { r } // if-then-else
| f(r...) // function application
| true | false // booleans
| r == r // equality
| r != r // not equal
| r < r // less than
| r <= r // less than or equal
| r > r // greater than
| r >= r // greater than or equal
| r || r // disjunction
| r && r // conjunction
| r => r // implication
| !r // negation
Index Refinements
Of the form i32[e] (i32 equal to e) values.
#[flux::sig(fn(bool[true]))]
pub fn assert(_b: bool) {}
pub fn test00() {
let x = 1;
let y = 2;
assert(x + 1 == y);
}
#[flux::sig(fn five() -> usize[5])]
pub fn five() -> usize {
let x = 2;
let y = 3;
x + y
}
#[flux::sig(fn(n:usize) -> usize[n+1])]
pub fn incr(n: usize) -> usize {
n + 1
}
pub fn test01() {
let a = five();
let b = incr(a);
assert(b == 6);
}NOTE: We use the sig(..) annotation to specify the refinement type of a function;
you can optionally also add the name of the function as shown for fn five.
Existential Refinements
Of the form i32{v: 0 <= v} (non-negative i32) values.
#[flux::spec(fn(x:i32) -> i32{v: v > x})]
pub fn inc(x: i32) -> i32 {
x + 1
}
#[flux::spec(fn(x:i32) -> i32{v: v < x})]
pub fn dec(x: i32) -> i32 {
x - 1
}Combining Index and Existential Refinements
#[flux::sig(fn(k: i32{0 <= k}) -> i32[0])]
pub fn test(mut k: i32) -> i32 {
while toss() && k < i32::MAX - 1 {
k += 1;
}
while k > 0 {
k -= 1;
}
k
}Mutable References
#[flux::sig(fn(x: &mut i32{v: 0 <= v}))]
pub fn test4(x: &mut i32) {
*x += 1;
}#[flux::sig(fn(x: &mut i32{v: 0 <= v}))]
pub fn test4(x: &mut i32) {
*x -= 1; //~ ERROR assignment might be unsafe
}Strong References
Like &mut T but which allow strong updates via ensures clauses
#[flux::sig(fn(x: &strg i32[@n]) ensures x: i32[n+1])]
pub fn inc(x: &mut i32) {
*x += 1;
}
#[flux::sig(fn() -> i32[1])]
pub fn test_inc() -> i32 {
let mut x = 0;
inc(&mut x);
x
}Mixing Mutable and Strong References
#[flux::sig(fn (x: &strg i32[@n]) ensures x: i32[n+1])]
pub fn incr(x: &mut i32) {
*x += 1;
}
#[flux::sig(fn (x: &mut i32{v: 0<=v}))]
pub fn client_safe(z: &mut i32) {
incr(z);
}Refined Arrays
flux supports refined arrays of the form [i32{v: 0 <= v}; 20]
denoting arrays of size 20 of non-negative i32 values.
#[flux::sig(fn() -> [i32{v : v >= 0}; 2])]
pub fn array00() -> [i32; 2] {
[0, 1]
}
pub fn read_u16() -> u16 {
let bytes: [u8; 2] = [10, 20];
u16::from_le_bytes(bytes)
}
#[flux::sig(fn() -> i32{v : v > 10})]
pub fn write() -> i32 {
let bytes: [i32; 2] = [10, 20];
bytes[0] + bytes[1]
}Refined Vectors rvec
RVec specification
#![allow(dead_code)]
pub mod rslice;
#[macro_export]
macro_rules! rvec {
() => { RVec::new() };
($($e:expr),+$(,)?) => {{
let mut res = RVec::new();
$( res.push($e); )*
res
}};
($elem:expr; $n:expr) => {{
RVec::from_elem_n($elem, $n)
}}
}
#[flux::opaque]
#[flux::refined_by(len: int)]
#[flux::invariant(0 <= len)]
pub struct RVec<T> {
inner: Vec<T>,
}
impl<T> RVec<T> {
#[flux::trusted]
#[flux::sig(fn() -> RVec<T>[0])]
pub fn new() -> Self {
Self { inner: Vec::new() }
}
#[flux::trusted]
#[flux::sig(fn(self: &strg RVec<T>[@n], T) ensures self: RVec<T>[n+1])]
pub fn push(&mut self, item: T) {
self.inner.push(item);
}
#[flux::trusted]
#[flux::sig(fn(&RVec<T>[@n]) -> usize[n])]
pub fn len(&self) -> usize {
self.inner.len()
}
#[flux::trusted]
#[flux::sig(fn(&RVec<T>[@n]) -> bool[n == 0])]
pub fn is_empty(&self) -> bool {
self.inner.is_empty()
}
#[flux::trusted]
#[flux::sig(fn(&RVec<T>[@n], i: usize{i < n}) -> &T)]
pub fn get(&self, i: usize) -> &T {
&self.inner[i]
}
#[flux::trusted]
#[flux::sig(fn(&mut RVec<T>[@n], i: usize{i < n}) -> &mut T)]
pub fn get_mut(&mut self, i: usize) -> &mut T {
&mut self.inner[i]
}
#[flux::trusted]
#[flux::sig(fn(self: &strg RVec<T>[@n]) -> T
requires n > 0
ensures self: RVec<T>[n-1])]
pub fn pop(&mut self) -> T {
self.inner.pop().unwrap()
}
#[flux::trusted]
#[flux::sig(fn(&mut RVec<T>[@n], a: usize{a < n}, b: usize{b < n}))]
pub fn swap(&mut self, a: usize, b: usize) {
self.inner.swap(a, b);
}
#[flux::trusted]
#[flux::sig(fn(&mut RVec<T>[@n]) -> &mut [T][n])]
pub fn as_mut_slice(&mut self) -> &mut [T] {
self.inner.as_mut_slice()
}
#[flux::trusted]
#[flux::sig(fn(arr:_) -> RVec<T>[N])]
pub fn from_array<const N: usize>(arr: [T; N]) -> Self {
Self { inner: Vec::from(arr) }
}
#[flux::trusted]
#[flux::sig(fn(xs:&[T][@n]) -> RVec<T>[n])]
pub fn from_slice(xs: &[T]) -> Self
where
T: Clone,
{
Self { inner: Vec::from(xs) }
}
#[flux::trusted]
#[flux::sig(fn(T, n: usize) -> RVec<T>[n])]
pub fn from_elem_n(elem: T, n: usize) -> Self
where
T: Copy,
{
let mut vec = Self::new();
let mut i = 0;
while i < n {
vec.push(elem);
i += 1;
}
vec
}
#[flux::trusted]
#[flux::sig(fn(&RVec<T>[@n]) -> RVec<T>[n])]
pub fn clone(&self) -> Self
where
T: Clone,
{
Self { inner: self.inner.clone() }
}
#[flux::trusted]
#[flux::sig(fn(self: &strg RVec<T>[@n], other: &[T][@m]) ensures self: RVec<T>[n + m])]
pub fn extend_from_slice(&mut self, other: &[T])
where
T: Clone,
{
self.inner.extend_from_slice(other)
}
#[flux::trusted]
#[flux::sig(fn (&RVec<T>[@n], F) -> RVec<U>[n])]
pub fn map<U, F>(&self, f: F) -> RVec<U>
where
F: Fn(&T) -> U,
{
RVec { inner: self.inner.iter().map(f).collect() }
}
#[flux::trusted]
pub fn fold<B, F>(&self, init: B, f: F) -> B
where
F: FnMut(B, &T) -> B,
{
self.inner.iter().fold(init, f)
}
}
#[flux::opaque]
pub struct RVecIter<T> {
vec: RVec<T>,
curr: usize,
}
impl<T> IntoIterator for RVec<T> {
type Item = T;
type IntoIter = RVecIter<T>;
// TODO: cannot get variant of opaque struct
#[flux::trusted]
#[flux::sig(fn(RVec<T>) -> RVecIter<T>)]
fn into_iter(self) -> RVecIter<T> {
RVecIter { vec: self, curr: 0 }
}
}
impl<T> Iterator for RVecIter<T> {
type Item = T;
// TODO: cannot get variant of opaque struct
#[flux::trusted]
#[flux::sig(fn(&mut RVecIter<T>) -> Option<T>)]
fn next(&mut self) -> Option<T> {
self.vec.inner.pop()
}
}
impl<T> std::ops::Index<usize> for RVec<T> {
type Output = T;
#[flux::trusted_impl]
#[flux::sig(fn(&RVec<T>[@n], usize{v : v < n}) -> &T)]
fn index(&self, index: usize) -> &T {
self.get(index)
}
}
impl<T> std::ops::IndexMut<usize> for RVec<T> {
#[flux::trusted_impl]
#[flux::sig(fn(&mut RVec<T>[@n], usize{v : v < n}) -> &mut T)]
fn index_mut(&mut self, index: usize) -> &mut T {
self.get_mut(index)
}
}RVec clients
#[path = "../../lib/rvec.rs"]
mod rvec;
use rvec::RVec;
#[flux::sig(fn() -> RVec<i32>[0])]
pub fn test0() -> RVec<i32> {
let mv = rvec![];
mv
}
#[flux::sig(fn() -> RVec<i32>[5])]
pub fn test1() -> RVec<i32> {
rvec![ 12; 5 ]
}
#[flux::sig(fn(n:usize) -> RVec<i32>[n])]
pub fn test2(n: usize) -> RVec<i32> {
rvec![ 12; n ]
}
pub fn test3() -> usize {
let v = rvec![0, 1];
let r = v[0];
let r = r + v[1];
r
}Binary Search
#![allow(unused_attributes)]
#[path = "../../lib/rvec.rs"]
pub mod rvec;
use rvec::RVec;
// CREDIT: https://shane-o.dev/blog/binary-search-rust
#[flux::sig(fn(i32, &RVec<i32>) -> usize)]
pub fn binary_search(k: i32, items: &RVec<i32>) -> usize {
let size = items.len();
if size <= 0 {
return size;
}
let mut low: usize = 0;
let mut high: usize = size - 1;
while low <= high {
// SAFE let middle = (high + low) / 2;
// UNSAFE let middle = high + ((high - low) / 2);
let middle = low + ((high - low) / 2);
let current = items[middle];
if current == k {
return middle;
}
if current > k {
if middle == 0 {
return size;
}
high = middle - 1
}
if current < k {
low = middle + 1
}
}
size
}Heapsort
#[path = "../../lib/rvec.rs"]
mod rvec;
use rvec::RVec;
#[flux::sig(fn(&mut RVec<i32>[@n]) -> i32)]
pub fn heap_sort(vec: &mut RVec<i32>) -> i32 {
let len = vec.len();
if len <= 0 {
return 0;
}
let mut start = len / 2;
while start > 0 {
start -= 1;
shift_down(vec, start, len - 1);
}
let mut end = len;
while end > 1 {
end -= 1;
vec.swap(0, end);
shift_down(vec, 0, end - 1);
}
0
}
#[flux::sig(fn(&mut RVec<i32>[@len], usize{v : v < len}, usize{v : v < len}) -> i32)]
pub fn shift_down(vec: &mut RVec<i32>, start: usize, end: usize) -> i32 {
let mut root = start;
loop {
let mut child = root * 2 + 1;
if child > end {
break;
} else {
if child + 1 <= end {
let a = vec[child];
let b = vec[child + 1];
if a < b {
child += 1;
}
}
let a = vec[root];
let b = vec[child];
if a < b {
vec.swap(root, child);
root = child;
} else {
break;
}
}
}
0
}Refined Slices
#[flux::sig(fn(&[i32{v : v > 0}]) -> &[i32{v : v >= 0}])]
fn first_half(slice: &[i32]) -> &[i32] {
let mid = slice.len() / 2;
let (fst, snd) = slice.split_at(mid);
fst
}
#[flux::sig(fn(&[i32{v : v > 0}]) -> Option<&i32{v : v >= 0}>)]
fn first(slice: &[i32]) -> Option<&i32> {
slice.first()
}
#[flux::sig(fn(&mut [i32{v : v > 0}]))]
fn inc_fst(slice: &mut [i32]) {
if let Some(x) = slice.first_mut() {
*x += 1;
}
}#[path = "../../lib/rvec.rs"]
mod rvec;
use rvec::{RVec, rslice::RSlice};
#[flux::sig(fn(&mut RVec<T>[10]))]
fn test00<T>(vec: &mut RVec<T>) {
let mut s = RSlice::from_vec(vec);
let s1 = s.subslice(0, 3);
let s2 = s.subslice(4, 5);
}
#[flux::trusted]
#[flux::sig(fn(x: &[T][@n]) -> usize[n])]
fn len<T>(x: &[T]) -> usize {
x.len()
}
#[flux::sig(fn(&mut [i32][@n], &[i32][n]))]
fn add(x: &mut [i32], y: &[i32]) {
let mut i = 0;
while i < len(x) {
x[i] += y[i];
i += 1;
}
}
#[flux::sig(fn(&mut {RVec<i32>[@n] | n % 2 == 0 && n > 0}))]
fn test01(vec: &mut RVec<i32>) {
let n = vec.len();
let mut s = RSlice::from_vec(vec);
let mut s1 = s.subslice(0, n / 2 - 1);
let s2 = s.subslice(n / 2, n - 1);
add(s1.as_mut_slice(), s2.as_slice())
}Refined Vec
This uses extern_spec which is described below.
Standalone
#![feature(allocator_api)]
extern crate flux_alloc;
extern crate flux_core;
use flux_rs::{assert, attrs::*};
#[spec(fn() -> Vec<i32>[3])]
pub fn test_vec_macro() -> Vec<i32> {
vec![10, 20, 30]
}
#[spec(fn() -> Vec<i32>[4])]
pub fn test_push_macro() -> Vec<i32> {
let res = vec![10, 20, 30, 40];
assert(res.len() == 4);
res
}
#[spec(fn() -> Vec<i32>[2])]
pub fn test_push() -> Vec<i32> {
let mut res = Vec::new();
res.push(10);
res.push(20);
res.push(30);
let val = res.pop().unwrap();
assert(val >= 10);
res
}
#[spec(fn() -> usize[2])]
pub fn test_len() -> usize {
let res = test_push();
res.len()
}
pub fn test_is_empty() {
let res = test_push();
assert(!res.is_empty())
}
// TODO: https://github.com/flux-rs/flux/issues/578
// #[spec(fn (Vec<i32{v:10 <= v}>))]
// pub fn test3(xs: Vec<i32>) {
// for x in &xs {
// assert(0 <= *x)
// }
// }
#[spec(fn (vec: &mut Vec<T>[@n]) -> Option<(T, T)>
requires n > 2
ensures vec: Vec<T>[n-2])]
pub fn pop2<T>(vec: &mut Vec<T>) -> Option<(T, T)> {
let v1 = vec.pop().unwrap();
let v2 = vec.pop().unwrap();
Some((v1, v2))
}Associated Refinements for indexing
use std::{
alloc::{Allocator, Global},
ops::{Deref, DerefMut, Index, IndexMut},
slice::SliceIndex,
};
use flux_attrs::*;
//---------------------------------------------------------------------------------------
#[extern_spec]
#[refined_by(len: int)]
#[invariant(0 <= len)]
struct Vec<T, A: Allocator = Global>;
//---------------------------------------------------------------------------------------
#[extern_spec]
impl<T> Vec<T> {
#[flux::sig(fn() -> Vec<T>[0])]
fn new() -> Vec<T>;
}
#[extern_spec]
impl<T, A: Allocator> Vec<T, A> {
#[spec(fn(self: &mut Vec<T, A>[@n], T) ensures self: Vec<T, A>[n+1])]
fn push(v: &mut Vec<T, A>, value: T);
#[spec(fn(&Vec<T, A>[@n]) -> usize[n])]
fn len(v: &Vec<T, A>) -> usize;
#[spec(fn(self: &mut Vec<T, A>[@n]) -> Option<T>[n > 0] ensures self: Vec<T, A>[if n > 0 { n-1 } else { 0 }])]
fn pop(&mut self) -> Option<T>;
#[spec(fn(self: &Vec<T, A>[@n]) -> bool[n == 0])]
fn is_empty(&self) -> bool;
}
#[extern_spec]
impl<T: Clone, A: Allocator + Clone> Clone for Vec<T, A> {
#[spec(fn(self: &Vec<T, A>[@n]) -> Vec<T, A>[n])]
fn clone(&self) -> Vec<T, A>;
}
//---------------------------------------------------------------------------------------
#[extern_spec]
impl<T, I: SliceIndex<[T]>, A: Allocator> Index<I> for Vec<T, A> {
#[assume_parametric(T)]
#[spec(fn(&Vec<T, A>[@len], {I[@idx] | <I as SliceIndex<[T]>>::in_bounds(idx, len)}) -> _)]
fn index(z: &Vec<T, A>, index: I) -> &<I as SliceIndex<[T]>>::Output;
}
#[extern_spec]
impl<T, I: SliceIndex<[T]>, A: Allocator> IndexMut<I> for Vec<T, A> {
#[assume_parametric(T)]
#[spec(fn(&mut Vec<T,A>[@len], {I[@idx] | <I as SliceIndex<[T]>>::in_bounds(idx, len)}) -> _)]
fn index_mut(z: &mut Vec<T, A>, index: I) -> &mut <I as SliceIndex<[T]>>::Output;
}
//---------------------------------------------------------------------------------------
#[extern_spec]
impl<'a, T, A: Allocator> IntoIterator for &'a Vec<T, A> {
#[spec(fn (&Vec<T, A>[@n]) -> <&Vec<T, A> as IntoIterator>::IntoIter[0,n])]
fn into_iter(v: &'a Vec<T, A>) -> <&'a Vec<T, A> as IntoIterator>::IntoIter;
}
#[extern_spec]
#[assoc(fn with_size(self: Self, n:int) -> bool { self.len == n })]
impl<T> FromIterator<T> for Vec<T> {}
// ---------------------------------------------------------------------------------------
#[extern_spec(std::vec)]
#[assoc(fn as_deref(v: Self, target: int) -> bool { v.len == target })]
impl<T, A: Allocator> Deref for Vec<T, A> {
#[sig(fn(self: &Self[@v]) -> &[T][v])]
fn deref(&self) -> &[T];
}
#[extern_spec(std::vec)]
impl<T, A: Allocator> DerefMut for Vec<T, A> {
#[sig(fn(self: &mut Self[@v]) -> &mut [T][v])]
fn deref_mut(&mut self) -> &mut [T];
}#![feature(allocator_api)]
use std::ops::Index;
extern crate flux_alloc;
extern crate flux_core;
// ---------------------------------------------------------------------------------------
pub fn test_get0(xs: &Vec<i32>) -> &i32 {
<Vec<i32> as Index<usize>>::index(xs, 10) //~ ERROR refinement type
}
pub fn test_get1(xs: &Vec<i32>) -> i32 {
xs[10] //~ ERROR refinement type
}
#[flux::sig(fn (&Vec<i32>[100]) -> &i32)]
pub fn test_get2(xs: &Vec<i32>) -> &i32 {
<Vec<i32> as Index<usize>>::index(xs, 99)
}
#[flux::sig(fn (&Vec<i32>[100]) -> i32)]
pub fn test_get3(xs: &Vec<i32>) -> i32 {
xs[99]
}
pub fn test_set0(xs: &mut Vec<i32>) {
xs[10] = 100; //~ ERROR refinement type
}
#[flux::sig(fn (&mut Vec<i32>[100]))]
pub fn test_set1(xs: &mut Vec<i32>) {
xs[99] = 100;
}
pub fn test1() {
let mut xs = Vec::<i32>::new();
xs.push(10);
xs.push(20);
xs.push(30);
xs[0] = 100;
xs[1] = 100;
xs[2] = 100;
xs[10] = 100; //~ ERROR refinement type
}
pub fn test2(xs: Vec<i32>, i: usize) {
if i < xs.len() {
let _ = xs[i];
let _ = xs[i + 1]; //~ ERROR refinement type
}
}Named Function Signatures
You can also write named function signatures using the spec
annotation (instead of the anonymous sig annotation).
Requires Clauses
Used to specify preconditions in a single spot, if needed.
#[path = "../../lib/rvec.rs"]
mod rvec;
use rvec::RVec;
#[flux::sig(
fn(&mut RVec<i32>[@n], b:bool) -> i32[0]
requires 2 <= n
)]
pub fn test1(vec: &mut RVec<i32>, b: bool) -> i32 {
let r;
if b {
r = &mut vec[0];
} else {
r = &mut vec[1];
}
*r = 12;
0
}Refining Structs
#![flux::defs {
qualifier Sub2(x: int, a: int, b:int) { x == a - b }
}]
#[path = "../../lib/rvec.rs"]
pub mod rvec;
use rvec::RVec;
#[flux::refined_by(x: int, y:int)]
pub struct Pair {
#[flux::field(i32[x])]
pub x: i32,
#[flux::field(i32[y])]
pub y: i32,
}
#[flux::sig(fn(a: i32) -> RVec<Pair{v : v.x + v.y <= a }>)]
pub fn mk_pairs_with_bound(a: i32) -> RVec<Pair> {
let mut i = 0;
let mut res = RVec::new();
while i < a {
let p = Pair { x: i, y: a - i };
res.push(p);
i += 1;
}
res
}#![flux::defs {
fn is_btwn(v:int, lo:int, hi: int) -> bool { lo <= v && v <= hi }
fn ok_day(d:int) -> bool { is_btwn(d, 1, 31) }
fn is_month30(m:int) -> bool { m == 4 || m == 6 || m == 9 || m == 11 }
fn ok_month(d:int, m:int) -> bool { is_btwn(m, 1, 12) && (is_month30(m) => d <= 30) }
fn is_leap_year(y:int) -> bool { y % 400 == 0 || (y % 4 == 0 && (y % 100) > 0) }
fn is_feb_day(d:int, y:int) -> bool { d <= 29 && ( d == 29 => is_leap_year(y) ) }
fn ok_year(d:int, m:int, y:int) -> bool { 1 <= y && (m == 2 => is_feb_day(d, y)) }
}]
// https://github.com/chrisdone/sandbox/blob/master/liquid-haskell-dates.hs
#[allow(dead_code)]
#[flux::refined_by(d:int, m:int, y:int)]
pub struct Date {
#[flux::field({ usize[d] | ok_day(d) })]
day: usize,
#[flux::field({ usize[m] | ok_month(d, m)})]
month: usize,
#[flux::field({ usize[y] | ok_year(d, m, y)})]
year: usize,
}
pub fn test() {
let _ok_date = Date { day: 9, month: 8, year: 1977 };
}
// TODO: Tedious to duplicate the definitions if you want to use them in rust code.
// Maybe some macro magic can unify?
#[flux::sig(fn(m:usize) -> bool[is_month30(m)])]
fn is_month30(m: usize) -> bool {
m == 4 || m == 6 || m == 9 || m == 11
}
#[flux::sig(fn(y:usize) -> bool[is_leap_year(y)])]
fn is_leap_year(y: usize) -> bool {
y % 400 == 0 || (y % 4 == 0 && y % 100 != 0)
}
#[flux::sig(fn(d:usize, y:usize) -> bool[is_feb_day(d, y)])]
fn is_feb_day(d: usize, y: usize) -> bool {
d <= 29 && (d != 29 || is_leap_year(y))
}
pub fn mk_date(day: usize, month: usize, year: usize) -> Option<Date> {
if 1 <= year && 1 <= month && month <= 12 && 1 <= day && day <= 31 {
if !is_month30(month) || day <= 30 {
if month != 2 || is_feb_day(day, year) {
return Some(Date { day, month, year });
}
}
}
return None;
}Invariants on Structs
#[flux::refined_by(a: int, b: int)]
#[flux::invariant(a > 0)]
#[flux::invariant(b > 0)]
pub struct S {
#[flux::field({i32[a] | a > 0})]
fst: i32,
#[flux::field({i32[b] | b >= a})]
snd: i32,
}with const generics
// Test that const generics in invariants are properly instantiated
use flux_attrs::*;
#[invariant(N > 0)]
struct S<const N: usize> {}
#[sig(fn(_) -> usize{v : v > 0})]
fn foo<const M: usize>(x: S<M>) -> usize {
M
}Opaque Structs
Flux offers an attribute opaque which can be used on structs. A module defining an opaque struct should define a trusted API, and clients of the API should not access struct fields directly. This is particularly useful in cases where users need to define a type indexed by a different type than the structs fields. For example, RMap (see below) defines a refined HashMap, indexed by a Map - a primitive sort defined by flux.
use flux_rs::*;
#[opaque]
#[refined_by(vals: Map<K, V>)]
pub struct RMap<K, V> {
inner: std::collections::HashMap<K, V>,
}Note that opaque structs can not have refined fields.
Now, we can define get for our refined map as follows:
impl<K, V> RMap<K, V> {
#[flux_rs::trusted]
#[flux_rs::sig(fn(&RMap<K, V>[@m], &K[@k]) -> Option<&V[map_select(m.vals, k)]>)]
pub fn get(&self, k: &K) -> Option<&V>
where
K: Eq + Hash,
{
self.inner.get(k)
}
}Note that if we do not mark these methods as trusted, we will get an error that looks like...
error[E0999]: cannot access fields of opaque struct `RMap`.
--> ../opaque.rs:22:9
|
22 | self.inner.get(k)
| ^^^^^^^^^^
-Ztrack-diagnostics: created at crates/flux-refineck/src/lib.rs:111:14
|
help: if you'd like to use fields of `RMap`, try annotating this method with `#[flux::trusted]`
--> ../opaque.rs:18:5
|
18 | / pub fn get(&self, k: &K) -> Option<&V>
19 | | where
20 | | K: Eq + std::hash::Hash,
| |________________________________^
= note: fields of opaque structs can only be accessed inside trusted code
Here is an example of how to use the opaque attribute:
#[flux::opaque]
#[flux::refined_by(a: int, b: int)]
#[flux::invariant(a <= b)]
pub struct Range {
a: i32,
b: i32,
}
impl Range {
#[flux::trusted]
#[flux::sig(fn(a: i32, b: i32{b >= a}) -> Range[a, b])]
pub fn new(a: i32, b: i32) -> Range {
Range { a, b }
}
#[flux::trusted]
#[flux::sig(fn(&Range[@r]) -> i32[r.a])]
pub fn fst(&self) -> i32 {
self.a
}
#[flux::trusted]
#[flux::sig(fn(&Range[@r]) -> i32[r.b])]
pub fn snd(&self) -> i32 {
self.b
}
}
#[flux::sig(fn(Range) -> bool[true])]
fn test(r: Range) -> bool {
r.snd() - r.fst() >= 0
}Refining Enums
#[flux::refined_by(b:bool)]
pub enum Opt<T> {
#[flux::variant(Opt<T>[false])]
None,
#[flux::variant({T} -> Opt<T>[true])]
Some(T),
}
#[flux::sig(fn(Opt<T>[@b]) -> bool[b])]
pub fn is_some<T>(x: Opt<T>) -> bool {
match x {
Opt::None => false,
Opt::Some(_) => true,
}
}
#[flux::sig(fn(Opt<T>[@b]) -> bool[b])]
pub fn is_some_flip<T>(x: Opt<T>) -> bool {
match x {
Opt::Some(_) => true,
Opt::None => false,
}
}
#[flux::sig(fn(i32{v:false}) -> T)]
pub fn never<T>(_x: i32) -> T {
loop {}
}
#[flux::sig(fn(Opt<T>[true]) -> T)]
pub fn unwrap<T>(x: Opt<T>) -> T {
match x {
Opt::Some(v) => v,
Opt::None => never(0),
}
}#[flux::refined_by(n: int)]
#[flux::invariant(n > 0)]
pub enum Pos {
#[flux::variant({Box<Pos[@n]>} -> Pos[2*n])]
XO(Box<Pos>),
#[flux::variant({Box<Pos[@n]>} -> Pos[2*n + 1])]
XI(Box<Pos>),
#[flux::variant(Pos[1])]
XH,
}
impl Pos {
#[flux::spec(fn(&Pos[@n]) -> i32[n])]
pub fn to_i32(&self) -> i32 {
match self {
Pos::XH => 1,
Pos::XI(rest) => 2 * rest.to_i32() + 1,
Pos::XO(rest) => 2 * rest.to_i32(),
}
}
#[flux::sig(fn(&Pos[@n]) -> bool[n == 1])]
pub fn is_one(&self) -> bool {
match self {
Pos::XH => true,
Pos::XI(_) => false,
Pos::XO(_) => false,
}
}
}#[flux::sig(fn(i32{v: false}) -> T)]
pub fn never<T>(_: i32) -> T {
loop {}
}
#[flux::refined_by(n:int)]
#[flux::invariant(n >= 0)]
pub enum List {
#[flux::variant(List[0])]
Nil,
#[flux::variant((i32, Box<List[@n]>) -> List[n+1])]
Cons(i32, Box<List>),
}
#[flux::sig(fn(&List[@n]) -> bool[n == 0])]
pub fn empty(l: &List) -> bool {
match l {
List::Nil => true,
List::Cons(_, _) => false,
}
}
#[flux::sig(fn(&List[@n]) -> i32[n])]
pub fn len(l: &List) -> i32 {
match l {
List::Nil => 0,
List::Cons(_, tl) => 1 + len(tl),
}
}
#[flux::sig(fn({&List[@n] | 0 < n}) -> i32)]
pub fn head(l: &List) -> i32 {
match l {
List::Nil => never(0),
List::Cons(h, _) => *h,
}
}
#[flux::sig(fn({&List[@n] | 0 < n}) -> &List)]
pub fn tail(l: &List) -> &List {
match l {
List::Nil => never(0),
List::Cons(_, t) => t,
}
}
#[flux::sig(fn(i32, n: usize) -> List[n])]
pub fn clone(val: i32, n: usize) -> List {
if n == 0 {
List::Nil
} else {
List::Cons(val, Box::new(clone(val, n - 1)))
}
}
#[flux::sig(fn(List[@n1], List[@n2]) -> List[n1+n2])]
pub fn append(l1: List, l2: List) -> List {
match l1 {
List::Nil => l2,
List::Cons(h1, t1) => List::Cons(h1, Box::new(append(*t1, l2))),
}
}
#[flux::sig(fn(l1: &strg List[@n1], List[@n2]) ensures l1: List[n1+n2])]
pub fn mappend(l1: &mut List, l2: List) {
match l1 {
List::Nil => *l1 = l2,
List::Cons(_, t1) => mappend(&mut *t1, l2),
}
}
#[flux::sig(fn(&List[@n], k:usize{k < n} ) -> i32)]
pub fn get_nth(l: &List, k: usize) -> i32 {
match l {
List::Cons(h, tl) => {
if k == 0 {
*h
} else {
get_nth(tl, k - 1)
}
}
List::Nil => never(0),
}
}Invariants on Enums
#[flux::refined_by(n: int)]
#[flux::invariant(n >= 0)]
pub enum E {
#[flux::variant({{i32[@n] | n > 0}} -> E[n])]
Pos(i32),
#[flux::variant({i32[0]} -> E[0])]
Zero(i32),
}
#[flux::sig(fn(E[@n], i32[n]) -> i32{v: v > 0})]
pub fn is_zero(_: E, x: i32) -> i32 {
x + 1
}Reflecting Enums
use flux_attrs::*;
#[reflect]
pub enum State {
On,
Off,
}
#[spec(fn () -> State[State::On])]
pub fn test00() -> State {
State::On
}
#[spec(fn () -> State[State::Off])]
pub fn test01() -> State {
State::Off
}
#[spec(fn () -> State[State::Off])]
pub fn test02() -> State {
State::On //~ ERROR refinement type
}
#[spec(fn (State[State::On]) -> usize[1])]
pub fn test03(s: State) -> usize {
match s {
State::On => 1,
State::Off => 0,
}
}
#[spec(fn (State[@squig], zig: usize, tag: Day) -> usize[tag])]
pub fn test04(s: State, _zig: usize, tag: Day) -> usize {
match s {
State::On => 1, //~ ERROR refinement type
State::Off => 0, //~ ERROR refinement type
}
}
#[refined_by(day: int)]
pub enum Day {
#[flux::variant(Day[0])]
Mon,
#[flux::variant(Day[1])]
Tue,
#[flux::variant(Day[2])]
Wed,
}
#[spec(fn (s:State, zig: usize, tag: Day) -> usize[tag])]
pub fn test05(s: State, _zig: usize, _tag: Day) -> usize {
match s {
State::On => 1, //~ ERROR refinement type
State::Off => 0, //~ ERROR refinement type
}
}Field Syntax for Indices
Structs
#[flux::refined_by(x: int, y: int)]
pub struct X {
#[flux::field(u32[x])]
x: u32,
#[flux::field(u32[y])]
y: u32,
}
#[flux::sig(fn (x: X[@old_x]) -> X[X { y: 2, x: 1 }])]
fn f(mut x: X) -> X {
x.x = 1;
x.y = 2;
x
}Enums
#[flux::refined_by(x: int, y: int)]
pub enum E {
#[flux::variant(E[0, 1])]
Variant1,
#[flux::variant(E[1, 2])]
Variant2,
#[flux::variant(E[2, 3])]
Variant3,
}
#[flux::sig(fn (e: E[@old_enum]) -> E[E { x: 1, y: 2 }])]
fn f(e: E) -> E {
E::Variant2
}Updates
#[flux::refined_by(x: int, y: int)]
pub struct S {
#[flux::field(u32[x])]
x: u32,
#[flux::field(u32[y])]
y: u32,
}
impl S {
#[flux::sig(fn (self: &strg S[@old_x]) ensures self: S[S { x: 1, ..old_x }])]
pub fn update(&mut self) {
self.x = 1;
}
}#![flux::defs {
fn some_computation(s: S) -> S { s }
}]
#[flux::refined_by(x: int, y: int)]
pub struct S {
#[flux::field(u32[x])]
x: u32,
#[flux::field(u32[y])]
y: u32,
}
impl S {
#[flux::sig(fn (self: &strg S[@old_x]) ensures self: S[S { x: 1, ..some_computation(old_x) }])]
pub fn update(&mut self) {
self.x = 1;
}
#[flux::sig(fn (self: &strg S[@old_x]) ensures self: S[S { x: 1, ..S { x: 2, ..old_x } }])]
pub fn update2(&mut self) {
self.x = 1;
}
}use flux_attrs::*;
#[refined_by(start: T, end: T)]
pub struct Range<T> {
#[flux::field(T[start])]
pub start: T,
#[flux::field(T[end])]
pub end: T,
}
#[sig(fn(r: Range<T>[@old]) -> Range<T>[ Range { ..old } ])]
pub fn foo<T>(r: Range<T>) -> Range<T> {
r
}
#[sig(fn(r: Range<i32>{v: v == Range { start: 0, end: 0 } }))]
pub fn foo2(_r: Range<i32>) {}
#[sig(fn(r: Range<i32>[Range { start: 0, end: 0 } ]))]
pub fn foo3(_r: Range<i32>) {}#![flux::defs {
fn some_computation(s: S) -> S { s }
}]
#[flux::refined_by(x: int, y: int)]
pub struct S {
#[flux::field(u32[x])]
x: u32,
#[flux::field(u32[y])]
y: u32,
}
impl S {
#[flux::sig(fn (self: &strg S[@old_x]) ensures self: S[{ x: 1, ..some_computation(old_x) }])]
pub fn update(&mut self) {
self.x = 1;
}
#[flux::sig(fn (self: &strg S[@old_x]) ensures self: S[{ x: 1, ..S { x: 2, ..old_x } }])]
pub fn update2(&mut self) {
self.x = 1;
}
}Const
You can use int-ish const in refinements e.g.
pub struct Cow {}
impl Cow {
const GRASS: usize = 12;
#[flux_rs::sig(fn () -> usize[12])]
pub fn test() -> usize {
Self::GRASS
}
}#[repr(u32)]
pub enum SyscallReturnVariant {
Failure = 0,
}
#[flux_rs::sig(fn() -> u32[0])]
pub fn test() -> u32 {
SyscallReturnVariant::Failure as u32
}pub struct Cow {}
const GRASS: usize = 12;
impl Cow {
#[flux_rs::sig(fn () -> usize[12])]
fn test() -> usize {
GRASS
}
}Requires with forall
We allow a forall on the requires clauses, e.g.
#[flux::sig(fn(bool[true]))]
fn assert(_: bool) {}
#[flux::trusted(reason = "skip special casing forall in assumption")]
#[flux::sig(
fn(x: i32)
requires forall y. y >= 0 => y > x
)]
fn requires_negative(x: i32) {
assert(x + 1 == 1 + x); // make sure there's something to check to avoid optimizing the entire constraint away
}
fn test2() {
requires_negative(-1);
}Refined Associated Types
use flux_rs::*;
#[sig(fn(bool[true]))]
fn assert(_: bool) {}
trait MyTrait {
type Assoc;
#[sig(fn(Self::Assoc[@x]) -> Self::Assoc[x])]
fn f0(x: Self::Assoc) -> Self::Assoc;
#[sig(fn(x: Self::Assoc) -> Self::Assoc{ v: v == x })]
fn f1(x: Self::Assoc) -> Self::Assoc;
}
impl MyTrait for () {
type Assoc = i32;
#[sig(fn(x: i32) -> i32[x])]
fn f0(x: i32) -> i32 {
x
}
#[sig(fn(x: i32) -> i32[x])]
fn f1(x: i32) -> i32 {
x
}
}
fn test00() {
let x = <() as MyTrait>::f0(0);
assert(x == 0);
}
fn test01() {
let x = <() as MyTrait>::f1(0);
assert(x == 0);
}Ignored and trusted code
Flux offers two attributes for controlling which parts of your code it analyzes: #[flux_rs::ignore] and #[flux_rs::trusted].
#[flux_rs::ignore]: This attribute is applicable to any item, and it instructs Flux to completely skip some code. Flux won't even look at it.#[flux_rs::trusted]: This attribute affects whether Flux checks the body of a function. If a function is marked as trusted, Flux won't verify its body against its signature. However, it will still be able to reason about its signature when used elsewhere.
The above means that an ignored function can only be called from ignored or trusted code, while a trusted function can also be called from analyzed code.
Both attributes apply recursively. For instance, if a module is marked as #[flux_rs::ignore], all its nested elements will also be ignored. This transitive behavior can be disabled by marking an item with #[flux_rs::ignore(no)]1, which will include all nested elements for analysis. Similarly,
the action of #[flux_rs::trusted] can be reverted using #[flux_rs::trusted(no)].
Consider the following example:
#[flux_rs::ignore]
mod A {
#[flux_rs::ignore(no)]
mod B {
mod C {
fn f1() {}
}
}
mod D {
fn f2() {}
}
fn f3() {}
}In this scenario, functions f2 and f3 will be ignored, while f1 will be analyzed.
A typical pattern when retroactively adding Flux annotations to existing code is to ignore an entire crate (using the inner attribute #![flux_rs::ignore] at the top of the crate) and then selectively include specific sections for analysis.
Here is an example
#![flux::ignore] // default to ignore for the entire crate
#[flux::ignore(no)] // include this module
mod included {
#[flux::sig(fn(bool[true]))]
pub fn assert(_: bool) {}
pub fn test1() {
// we are indeed checking this code
assert(20 < 10); //~ ERROR refinement type error
}
pub fn test2() {
// we cannot use an ignored function in included code
crate::ignored_fun(); //~ERROR use of ignored function
}
}
// bad refinement, but no error since we are ignoring this function
#[flux::sig(fn(i32, i32))]
pub fn malformed(_: i32) {}
// an ignored function that cannot be used in included code
pub fn ignored_fun() {}Pragma: should_fail
Used to tell flux to expect a failure when checking a function.
// This function has an error
// but it's marked as should_fail so that ok.
// flux would yell if instead it verified!
#[flux::should_fail]
#[flux::sig(fn(x: i32) -> i32[x + 1])]
fn test00(x: i32) -> i32 {
x + 2
}Const Generics
flux lets you use Rust's const-generics inside refinements.
Refining Array Lengths
// https://github.com/flux-rs/flux/issues/625
const BUFLEN: usize = 100;
pub struct Blob {
data: [i32; BUFLEN],
}
pub fn test(buf: &[i32; BUFLEN]) -> i32 {
let x0 = buf[0];
let x1 = buf[10];
let x2 = buf[BUFLEN - 1];
let xbad = buf[BUFLEN]; //~ ERROR assertion might fail
x0 + x1 + x2 + xbad
}
pub fn test_blob(blob: Blob) -> i32 {
let x0 = blob.data[0];
let x1 = blob.data[10];
let x2 = blob.data[BUFLEN - 1];
let xbad = blob.data[BUFLEN]; //~ ERROR assertion might fail
x0 + x1 + x2 + xbad
}Refining Struct Fields
#[flux::invariant(N > 0)]
pub struct MPU<const N: usize> {
#[flux::field({ i32 | N > 0 })]
field: i32,
}
pub fn foo<const N: usize>(x: usize, _mpu: MPU<N>) {
let _x = x % N;
}
#[flux::invariant(N > 0)]
pub struct MPUGOOD<const N: usize> {
field: i32,
}
pub fn bar<const N: usize>(x: usize, _mpu: MPUGOOD<N>) {
let _x = x % N;
}
pub fn baz<const N: usize>() -> i32 {
if N > 0 {
let mpu = MPUGOOD::<N> { field: 12 };
mpu.field
} else {
0
}
}Refining Function Signatures
#[path = "../../lib/rvec.rs"]
mod rvec;
use rvec::RVec;
/// A statically sized matrix represented with a linear vector
struct Matrix<const N: usize, const M: usize> {
#[flux::field(RVec<i32>[N * M])]
inner: RVec<i32>,
}
impl<const N: usize, const M: usize> Matrix<N, M> {
fn new() -> Matrix<N, M> {
Matrix { inner: RVec::from_elem_n(0, N * M) }
}
#[flux::sig(fn(&mut Self, i: usize{ i < N }, j: usize{ j < M }, v: i32))]
fn set(&mut self, i: usize, j: usize, v: i32) {
self.inner[i * M + j] = v
}
#[flux::sig(fn(&Self, i: usize{ i < N }, j: usize{ j < M }) -> i32)]
fn get(&self, i: usize, j: usize) -> i32 {
self.inner[i * M + j]
}
}Type Aliases
You can define refined type aliases for Rust types.
Note
- They are connected to an underlying Rust type,
- They may also be parameterized by refinements, e.g.
Lb - There are two different kinds of parametrizations
- early (
Nat) and - late (
Lb).
- early (
#[flux::alias(type Nat[n: int] = {i32[n] | 0 <= n})]
type Nat = i32;
#[flux::alias(type Lb(n: int)[v: int] = {i32[v] | n <= v})]
type Lb = i32;
#[flux::sig(fn(x: Nat) -> Nat)]
pub fn test1(x: Nat) -> Nat {
x + 1
}
#[flux::sig(fn(x: Lb(10)) -> Lb(10))]
pub fn test2(x: Lb) -> Lb {
x + 1
}Spec Function Definitions
You can define spec functions that abstract complicated refinements into refinement-level functions, which can then be used in refinements.
Plain Expressions
#![flux::defs {
fn is_btwn(v:int, lo:int, hi: int) -> bool { lo <= v && v <= hi }
fn ok_day(d:int) -> bool { is_btwn(d, 1, 31) }
fn is_month30(m:int) -> bool { m == 4 || m == 6 || m == 9 || m == 11 }
fn ok_month(d:int, m:int) -> bool { is_btwn(m, 1, 12) && (is_month30(m) => d <= 30) }
fn is_leap_year(y:int) -> bool { y % 400 == 0 || (y % 4 == 0 && (y % 100) > 0) }
fn is_feb_day(d:int, y:int) -> bool { d <= 29 && ( d == 29 => is_leap_year(y) ) }
fn ok_year(d:int, m:int, y:int) -> bool { 1 <= y && (m == 2 => is_feb_day(d, y)) }
}]
// https://github.com/chrisdone/sandbox/blob/master/liquid-haskell-dates.hs
#[allow(dead_code)]
#[flux::refined_by(d:int, m:int, y:int)]
pub struct Date {
#[flux::field({ usize[d] | ok_day(d) })]
day: usize,
#[flux::field({ usize[m] | ok_month(d, m)})]
month: usize,
#[flux::field({ usize[y] | ok_year(d, m, y)})]
year: usize,
}
pub fn test() {
let _ok_date = Date { day: 9, month: 8, year: 1977 };
}
// TODO: Tedious to duplicate the definitions if you want to use them in rust code.
// Maybe some macro magic can unify?
#[flux::sig(fn(m:usize) -> bool[is_month30(m)])]
fn is_month30(m: usize) -> bool {
m == 4 || m == 6 || m == 9 || m == 11
}
#[flux::sig(fn(y:usize) -> bool[is_leap_year(y)])]
fn is_leap_year(y: usize) -> bool {
y % 400 == 0 || (y % 4 == 0 && y % 100 != 0)
}
#[flux::sig(fn(d:usize, y:usize) -> bool[is_feb_day(d, y)])]
fn is_feb_day(d: usize, y: usize) -> bool {
d <= 29 && (d != 29 || is_leap_year(y))
}
pub fn mk_date(day: usize, month: usize, year: usize) -> Option<Date> {
if 1 <= year && 1 <= month && month <= 12 && 1 <= day && day <= 31 {
if !is_month30(month) || day <= 30 {
if month != 2 || is_feb_day(day, year) {
return Some(Date { day, month, year });
}
}
}
return None;
}let binders
use flux_attrs::*;
defs! {
fn times2(x: int) -> int {
x * 2
}
fn test(x: int) -> int {
let y = times2(x);
let z = times2(y);
z * z * y
}
}
#[sig(fn() -> i32[test(10)])]
fn test() -> i32 {
32000
}Bounded Quantification
#![flux::defs {
fn magic(xing:int, yonk:int) -> bool;
fn magic_all(noob:int) -> bool {
forall i in 0 .. 4 {
magic(i, noob)
}
}
fn magic_ex(n:int) -> bool {
exists i in 0 .. 4 {
i == n
}
}
fn sorted_all(noob:int) -> bool {
forall i:int in 0 .. 4 {
magic(i, noob)
}
}
}]
#[flux::trusted]
#[flux::sig(fn(x:i32, y:i32) ensures magic(x, y))]
pub fn do_magic(_x: i32, _y: i32) {}
#[flux::trusted]
#[flux::sig(fn(x:i32, y:i32) ensures magic(x, y))]
pub fn do_sorted_magic(_x: i32, _y: i32) {}
// forall tests ----------------------------------------------------------------
#[flux::sig(fn({i32[@n] | magic_all(n)}) ensures magic(3, n))]
pub fn test_all_l(_x: i32) {}
#[flux::sig(fn(n:i32) ensures magic_all(n))]
pub fn test_all_r(n: i32) {
do_magic(0, n);
do_magic(1, n);
do_magic(2, n);
do_magic(3, n);
}
// exists tests ----------------------------------------------------------------
#[flux::sig(fn({i32[@n] | magic_ex(n)}) -> bool[true])]
pub fn test_exi_l(n: i32) -> bool {
n == 0 || n == 1 || n == 2 || n == 3
}
#[flux::sig(fn(n:i32) -> bool[magic_ex(n)])]
pub fn test_exi_r(n: i32) -> bool {
n == 0 || n == 1 || n == 2 || n == 3
}No Cycles!
However, there should be no cyclic dependencies in the function definitions.
#![flux::defs {
fn even(x: int) -> bool { x == 0 || odd(x-1) }
fn odd(x: int) -> bool { x == 1 || even(x-1) } //~ ERROR cycle
}]
#[flux::sig(fn(x:i32) -> i32[x+1])]
pub fn test(x: i32) -> i32 {
x + 1
}Uninterpreted Function Declarations
You can also declare uninterpreted functions -- about which flux knows nothing
other than the congruence property -- and then use them in refinements. Note that
in this case you have to use a trusted annotation for the function (e.g. is_valid)
that asserts facts over the uninterpreted function
#![flux::defs {
fn valid(x:int) -> bool;
}]
#[flux::trusted]
#[flux::sig(fn(x:i32) -> bool[valid(x)])]
fn is_valid(x: i32) -> bool {
0 <= x && x <= 100
}
#[flux::sig(fn (i32{v:valid(v)}) -> i32)]
fn bar(a: i32) -> i32 {
return a;
}
#[flux::sig(fn(i32))]
pub fn test(n: i32) {
let ok = is_valid(n);
if ok {
bar(n);
}
}#![flux::defs {
fn foo(x:int, y:int) -> int;
}]
#[flux::trusted]
#[flux::sig(fn(x: i32, y:i32) -> i32[foo(x, y)])]
fn foo(x: i32, y: i32) -> i32 {
x + y
}
#[flux::sig(fn (i32[foo(10, 20)]) -> i32)]
fn bar(a: i32) -> i32 {
return a;
}
#[flux::sig(fn())]
pub fn test() {
let a = 10;
let b = 20;
let c = foo(a, b);
bar(c);
}Hiding and Revealing Function Definitions
By default all the function definitions are either inlined or sent to the SMT solver
as define-fun (when run with FLUX_SMT_DEFINE_FUN=1). Sometimes we want to hide the
definition because reasoning about those functions can kill the solver -- or the function
is super complex and we just want to reason about it via congruence. For that you can
- use the
#[hide]attribute at the spec function definition, to make the function uninterpreted by default, and - use the
#[reveal]attribute at specific Rust function definition, to indicate you want to use the actual definition when checking that Rust function.
#![flux::defs {
#[hide]
fn mod33(n:int) -> int {
n % 33
}
#[hide]
fn foo(n:int, k:int) -> bool {
mod33(n) == k
}
}]
#[flux::sig(fn (a:i32) requires foo(a, 7))]
pub fn assert_foo(_a: i32) {}
#[flux::reveal(foo, mod33)]
pub fn use_foo(n: i32) {
if n == 40 {
assert_foo(n)
// without `reveal(foo)` we want to see an error in the above line.
}
}
#[flux::sig(fn (xs: &[i32{v: foo(v, 7)}][100]) -> i32{v : foo(v, 7)})]
pub fn bar(xs: &[i32]) -> i32 {
xs[0] // `foo` as uninterpreted works fine
}Spec Functions in SMTLIB
By default flux inlines all such function definitions.
Monomorphic functions may optionally be encoded
as functions in SMT by using the FLUX_SMT_DEFINE_FUN=1
environment variable.
Type Holes
You can (sometimes!) use _ in the flux signatures to omit the Rust components, e.g.
Function Signatures
#[flux::sig(fn(_) -> Option<_>)]
fn test00(x: i32) -> Option<i32> {
Some(x)
}
#[flux::sig(fn(x: &strg _) ensures x: i32[0])]
fn test01(x: &mut i32) {
*x = 0;
}
#[flux::sig(fn(x: &strg i32) ensures x: _)]
fn test02(x: &mut i32) {
*x = 0;
}Structs and Enums
// Type holes in structs and enums
pub struct S {
#[flux::field(Option<_>)]
x: Option<i32>,
}
pub fn test_s(s: S) -> Option<i32> {
s.x
}
pub enum E {
#[flux::variant((_) -> E)]
A(i32),
}
pub fn test_e(e: E) -> i32 {
match e {
E::A(x) => x,
}
}Type Aliases
#[flux::alias(type Test = Vec<_>)]
type Test = Vec<i32>;
fn test(x: Test) -> Vec<i32> {
x
}Generic Args
#[flux_rs::refined_by(m: Map<int, int>)]
#[flux_rs::opaque]
pub struct S1<const N: usize> {
_arr: [usize; N],
}
const MY_N: usize = 10;
#[flux_rs::refined_by(gloop: S1)]
pub struct S2 {
#[field(S1<_>[gloop])]
pub s1: S1<MY_N>,
}
#[flux_rs::refined_by(zoo: S1)]
pub struct S3<const M: usize> {
#[field(S1<_>[zoo])]
pub s1: S1<M>,
}Closures
use flux_attrs::*;
#[trusted]
#[spec(fn(c: Option<bool>) -> Option<i32{v:0 <= v}>)]
pub fn test0(c: Option<bool>) -> Option<i32> {
c.map(|b| if b { 1 } else { 2 })
}
// pub fn test0_buddy(x: i32) -> i32 {
// x + 1
// }
// #[flux::sig(fn(c: Option<bool>) -> Option<i32{v:1 <= v}>)]
// pub fn test1(c: Option<bool>) -> Option<i32> {
// c.map(|b| if b { 1 } else { 2 })
// }
// #[flux::sig(fn(c: Option<bool[true]>) -> Option<i32[1]>)]
// pub fn test2(c: Option<bool>) -> Option<i32> {
// c.map(|b| if b { 1 } else { 2 })
// }
// #[flux::sig(fn(n:usize) -> usize[n + 2])]
// pub fn test3(n: usize) -> usize {
// checked_add(n, 1)
// .and_then(|m| Some(m + 1))
// .expect("overflow")
// }
// #[flux::trusted]
// #[flux::sig(fn(n:usize, m:usize) -> Option<usize[n + m]>)]
// pub fn checked_add(n: usize, m: usize) -> Option<usize> {
// n.checked_add(m)
// }#[path = "../../lib/rvec.rs"]
mod rvec;
use rvec::RVec;
#[flux::trusted]
fn smap<S, F, A, B>(s: S, v: Vec<A>, f: F) -> Vec<B>
where
F: Fn(S, A) -> B,
S: Copy,
{
v.into_iter().map(|x| f(s, x)).collect()
}
#[flux::sig(fn(vs: Vec<i32{v:0<=v}>) -> Vec<i32{v:3<=v}>)]
pub fn test1_old(vs: Vec<i32>) -> Vec<i32> {
let st = 3;
smap(st, vs, |s, x| s + x)
}
#[flux::sig(fn(vs: Option<i32{v:0<=v}>) -> Option<i32{v:3<=v}>)]
pub fn test2_old(vs: Option<i32>) -> Option<i32> {
let y = 1;
let z = 2;
vs.map(|x| x + y + z)
}
pub struct Foo {
#[flux::field(i32{v: 10 <= v})]
pub val: i32,
}
pub fn test1(c: Option<bool>) -> Option<Foo> {
let x = 6;
let y = 10;
c.map(|b| if b { Foo { val: x + y } } else { Foo { val: 20 } })
}
#[flux::sig(fn(vec:&RVec<i32{v: 10 <= v}>{v: 0 < v}) -> Foo)]
fn bob(vec: &RVec<i32>) -> Foo {
Foo { val: vec[0] }
}
pub fn test2(c: Option<bool>) -> Option<Foo> {
let vec = rvec![100, 200, 300];
c.map(|b| if b { bob(&vec) } else { Foo { val: 20 } })
}
#[flux::trusted]
fn frob(_vec: &RVec<RVec<i32>>) -> Foo {
todo!()
}
pub fn test3(c: Option<bool>, vec: RVec<RVec<i32>>) -> Option<Foo> {
// let mut vec = rvec![rvec![100, 200, 300]];
c.map(|b| if b { frob(&vec) } else { Foo { val: 20 } })
}Function Pointers
#![allow(unused)]
#[flux::sig(fn (x:usize) -> usize[x+1])]
fn inc(x: usize) -> usize {
x + 1
}
#[flux::sig(fn(c: Option<usize[99]>) -> Option<usize[100]>)]
pub fn test_ok(c: Option<usize>) -> Option<usize> {
c.map(inc)
}#![allow(unused)]
fn id<T>(x: T) -> T {
x
}
#[flux::sig(fn(c: Option<usize[99]>) -> Option<usize[99]>)]
pub fn test_ok(c: Option<usize>) -> Option<usize> {
c.map(id)
}
#[flux::sig(fn(Option<i32[99]>) -> Option<i32[99]>)]
fn test_also_ok(x: Option<i32>) -> Option<i32> {
let f = id;
x.map(f)
}use flux_attrs::*;
#[sig(fn(x: i32{x > 0}) -> i32[1/x])]
fn div(x: i32) -> i32 {
1 / x
}
fn apply<A, B>(f: impl FnOnce(A) -> B, x: A) -> B {
f(x)
}
#[sig(fn() -> i32[0])]
fn test() -> i32 {
apply(div, 10)
}Traits and Implementations
pub trait MyTrait {
fn foo() -> i32;
fn bar();
}
pub struct MyTy;
impl MyTrait for MyTy {
#[flux::sig(fn () -> i32[10])]
fn foo() -> i32 {
10
}
fn bar() {}
}
#[flux::sig(fn () -> i32[10])]
pub fn test() -> i32 {
let n = MyTy::foo();
MyTy::bar();
n
}pub trait Mono {
#[flux::sig(fn (zing: &strg i32[@n]) ensures zing: i32{v:n < v})]
fn foo(z: &mut i32);
}
pub struct Tiger;
impl Mono for Tiger {
#[flux::sig(fn (pig: &strg i32[@m]) ensures pig: i32{v:m < v})]
fn foo(pig: &mut i32) {
*pig += 1;
}
}
pub struct Snake;
impl Mono for Snake {
#[flux::sig(fn (pig: &strg i32[@m]) ensures pig: i32[m+1])]
fn foo(pig: &mut i32) {
*pig += 1;
}
}pub trait Mono {
#[flux::sig(fn (zing: &strg i32[@n])
requires 100 < n
ensures zing: i32{v:n < v})]
fn foo(z: &mut i32);
}
pub struct Tiger;
impl Mono for Tiger {
#[flux::sig(fn (pig: &strg i32[@m])
requires 0 < m
ensures pig: i32{v:m < v})]
fn foo(pig: &mut i32) {
*pig += 1;
}
}
pub struct Snake;
impl Mono for Snake {
#[flux::sig(fn (pig: &strg {i32[@m] | 0 < m})
ensures pig: i32[m+1])]
fn foo(pig: &mut i32) {
*pig += 1;
}
}pub trait MyTrait {
#[flux::sig(fn[hrn p: Self -> bool](&Self{v: p(v)}) -> Self{v: p(v)})]
fn foo1(&self) -> Self;
fn foo2(&self) -> Self;
}
impl MyTrait for i32 {
// TODO: error-message when below is missing (currently: fixpoint crash!) see tests/tests/todo/trait13.rs
#[flux::sig(fn[hrn p: Self -> bool](&Self{v: p(v)}) -> Self{v: p(v)})]
fn foo1(&self) -> Self {
*self
}
#[flux::sig(fn[hrn q: Self -> bool](&Self{v: q(v)}) -> Self{v: q(v)})]
fn foo2(&self) -> Self {
*self
}
}
#[flux::sig(fn[hrn q: T -> bool](&T{v:q(v)}) -> T{v: q(v)})]
pub fn bar1<T: MyTrait>(x: &T) -> T {
x.foo1()
}
#[flux::sig(fn(bool[true]))]
fn assert(_b: bool) {}
pub fn test() {
let x = 42;
assert(bar1(&x) == 42);
assert(x.foo2() == 42);
}pub trait Silly<A> {
#[flux::sig(fn(&Self, z: A) -> i32{v:100 < v})]
fn bloop(&self, z: A) -> i32;
}
impl Silly<bool> for i32 {
#[flux::sig(fn(&Self, b : bool) -> i32[2000])]
fn bloop(&self, _b: bool) -> i32 {
2000
}
}
#[flux::sig(fn(i32) -> i32{v: 100 < v})]
pub fn client(x: i32) -> i32 {
let y = x.bloop(true);
y + 1
}
#[flux::sig(fn(_, _) -> i32{v:100 < v})]
pub fn client2<A, B: Silly<A>>(x: B, y: A) -> i32 {
x.bloop(y)
}Impl Trait
pub fn test1() -> impl Iterator<Item = i32> {
Some(10).into_iter()
}
#[flux::sig(fn () -> impl Iterator<Item = i32{v:1<=v}>)]
pub fn test2() -> impl Iterator<Item = i32> {
Some(10).into_iter()
}
#[flux::sig(fn () -> impl Iterator<Item = i32{v:1<=v}>)]
pub fn test_lib() -> impl Iterator<Item = i32> {
Some(10).into_iter()
}
#[flux::sig(fn () -> Option<i32{v:0<=v}>)]
pub fn test_client() -> Option<i32> {
let mut it = test_lib();
it.next()
}#[flux::sig(fn (x:i32) -> impl Iterator<Item = i32{v:x<=v}>)]
pub fn lib(x: i32) -> impl Iterator<Item = i32> {
Some(x).into_iter()
}
#[flux::sig(fn (k:i32) -> Option<i32{v:k<=v}>)]
pub fn test_client(k: i32) -> Option<i32> {
let mut it = lib(k);
it.next()
}Dynamic Trait Objects
#![allow(unused)]
// ------------------------------------------------------
trait Shape {
#[flux::sig(fn(self: _) -> i32{v: 0 <= v})]
fn vertices(&self) -> i32;
}
// ------------------------------------------------------
struct Circle {}
impl Shape for Circle {
#[flux::sig(fn(self: _) -> i32{v: 0 <= v})]
fn vertices(&self) -> i32 {
0
}
}
// ------------------------------------------------------
#[flux::sig(fn(shape: _) -> i32{v: 0 <= v})]
fn count(shape: &dyn Shape) -> i32 {
shape.vertices()
}
#[flux::sig(fn(shape: _) -> i32{v: 10 <= v})]
fn count_bad(shape: &dyn Shape) -> i32 {
shape.vertices() //~ ERROR: refinement type
}
fn main() {
let c = Circle {};
count(&c);
count_bad(&c);
}Generic Refinements
flux supports generic refinements see this paper for details
Horn Refinements
// Define a function whose type uses the Horn generic refinement `p`
#[flux::sig(
fn[hrn p: int -> bool](x: i32, y: i32) -> i32{v: p(v) && v >= x && v >= y}
requires p(x) && p(y)
)]
fn max(x: i32, y: i32) -> i32 {
if x > y { x } else { y }
}
// A client of `max` where the generic is instantiated to `|v| {v % 2 == 0}`
#[flux::sig(fn() -> i32{v: v % 2 == 0})]
pub fn test00() -> i32 {
max(4, 10)
}
// A client of `max` where the generic is instantiated to `|v| {v == 4 || v == 10}`
#[flux::sig(fn() -> i32[10])]
pub fn test01() -> i32 {
max(4, 10)
}#[flux::refined_by(a: int, b: int, hrn p: (int, int) -> bool)]
struct Pair {
#[flux::field(i32[a])]
fst: i32,
#[flux::field({i32[b] | p(a, b)})]
snd: i32,
}
#[flux::sig(fn() -> Pair)]
fn test00() -> Pair {
Pair { fst: 0, snd: 1 }
}
#[flux::sig(fn(Pair[@a, @b, |a, b| a < b]) -> i32{v: v > 0})]
fn test01(pair: Pair) -> i32 {
pair.snd - pair.fst
}
fn test02() {
let pair = Pair { fst: 0, snd: 1 };
let x = test01(pair);
}
#[flux::sig(fn(x: i32, Pair[@a, @b, |a, b| a > x]) -> i32{v: v > x})]
fn test03(x: i32, pair: Pair) -> i32 {
pair.fst
}
fn test04() {
let pair = Pair { fst: 10, snd: 0 };
test03(0, pair);
}#[derive(Clone, Copy)]
#[flux::refined_by(hrn p: int -> bool)]
pub struct S;
#[flux::sig(fn(x: i32) -> S[|y| y > x])]
pub fn gt(x: i32) -> S {
S
}
#[flux::sig(fn(x: i32) -> S[|y| y < x])]
pub fn lt(x: i32) -> S {
S
}
#[flux::sig(fn(S[@p1], S[@p2]) -> S[|x| p1(x) || p2(x)])]
pub fn or(_: S, _: S) -> S {
S
}
#[flux::sig(fn(S[@p], x: i32{ p(x) }))]
pub fn check(_: S, x: i32) {}
pub fn test() {
let s = or(gt(10), lt(0));
check(s, 11);
check(s, -1);
}Hindley Refinements
TODO
Bitvector Refinements
Operators
// https://github.com/flux-rs/flux/issues/1010
use flux_rs::{attrs::*, bitvec::BV32};
#[sig(fn (x:BV32{x == 1}) ensures (bv_shl(x, 3) == 8))]
pub fn test_shl_a(_x: BV32) {}
#[sig(fn (x:BV32{x == 1}) ensures (x << 3 == 8))]
pub fn test_shl_b(_x: BV32) {}
#[sig(fn (x:BV32{x == 8}) ensures (bv_lshr(x, 3) == 1))]
pub fn test_shr_a(_x: BV32) {}
#[sig(fn (x:BV32{x == 8}) ensures (x >> 3 == 1))]
pub fn test_shr_b(_x: BV32) {}
#[sig(fn (x:BV32{x == 8}) ensures (bv_or(x, 3) == 11))]
pub fn test_or_a(_x: BV32) {}
#[sig(fn (x:BV32{x == 8}) ensures (x | 3 == 11))]
pub fn test_or_b(_x: BV32) {}
#[sig(fn (x:BV32{x == 10}) ensures (bv_and(x, 3) == 2))]
pub fn test_and_a(_x: BV32) {}
#[sig(fn (x:BV32{x == 10}) ensures (x & 3 == 2))]
pub fn test_and_b(_x: BV32) {}use flux_rs::{attrs::*, bitvec::BV32};
#[sig(fn(x: BV32) -> BV32[bv_add(x, bv_int_to_bv32(1))])]
pub fn test_00(x: BV32) -> BV32 {
x + BV32::new(1)
}
#[sig(fn(x: BV32) -> BV32[x + bv_int_to_bv32(1)])]
pub fn test_01(x: BV32) -> BV32 {
x + BV32::new(1)
}
#[sig(fn(x: BV32) -> BV32[x + 1])]
pub fn test_02(x: BV32) -> BV32 {
x + BV32::new(1)
}
#[sig(fn(x: i32) -> i32[x + (1 + 2)])]
pub fn test_03(x: i32) -> i32 {
x + 3
}
#[sig(fn() -> BV32[bv_int_to_bv32(0x5)])]
pub fn test_04() -> BV32 {
BV32::new(0x5)
}
#[sig(fn() -> BV32[5])]
pub fn test_05() -> BV32 {
BV32::new(0x5)
}
#[sig(fn(x: BV32, y:BV32) -> bool[x + y > 5])]
pub fn test_06(x: BV32, y: BV32) -> bool {
x + y > BV32::new(5)
}
#[sig(fn(x: BV32, y:BV32) -> bool[x + y > x - y])]
pub fn test_07(x: BV32, y: BV32) -> bool {
x + y > x - y
}extern crate flux_core;
use std::ops::{Add, Sub};
#[flux::opaque]
#[flux::refined_by(x: bitvec<32>)]
pub struct BV32(u32);
impl BV32 {
#[flux::trusted]
#[flux::sig(fn (u32[@x]) -> BV32[bv_int_to_bv32(x)])]
pub fn new(x: u32) -> Self {
BV32(x)
}
}
impl Add for BV32 {
type Output = BV32;
#[flux_rs::trusted]
#[flux_rs::sig(fn (BV32[@val1], BV32[@val2]) -> BV32[bv_add(val1, val2)])]
fn add(self, rhs: Self) -> BV32 {
BV32(self.0 + rhs.0)
}
}
impl Sub for BV32 {
type Output = BV32;
#[flux_rs::trusted]
#[flux_rs::sig(fn (BV32[@val1], BV32[@val2]) -> BV32[bv_sub(val1, val2)])]
fn sub(self, rhs: Self) -> BV32 {
BV32(self.0.wrapping_add(!rhs.0))
}
}
impl PartialEq for BV32 {
fn eq(&self, other: &Self) -> bool {
self.0 == other.0
}
}
flux_core::eq!(
#[trusted]
BV32
);
impl PartialOrd for BV32 {
#[flux::trusted]
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
self.0.partial_cmp(&other.0)
}
#[flux::trusted]
#[flux::sig(fn (&BV32[@x], &BV32[@y]) -> bool[bv_ule(x, y)])]
fn le(&self, other: &Self) -> bool {
self.0 <= other.0
}
#[flux::trusted]
#[flux::sig(fn (&BV32[@x], &BV32[@y]) -> bool[bv_ult(x, y)])]
fn lt(&self, other: &Self) -> bool {
self.0 < other.0
}
#[flux::trusted]
#[flux::sig(fn (&BV32[@x], &BV32[@y]) -> bool[bv_uge(x, y)])]
fn ge(&self, other: &Self) -> bool {
self.0 >= other.0
}
#[flux::trusted]
#[flux::sig(fn (&BV32[@x], &BV32[@y]) -> bool[bv_ugt(x, y)])]
fn gt(&self, other: &Self) -> bool {
self.0 > other.0
}
}
#[flux::sig(fn (BV32[@x]) -> bool[bv_ule(x, x)])]
pub fn trivial_le(x: BV32) -> bool {
x <= x
}
#[flux::sig(fn (BV32[@x]) -> bool[bv_ult(x, x)])]
pub fn trivial_lt(x: BV32) -> bool {
x < x
}
#[flux::sig(fn (BV32[@x]) -> bool[bv_uge(x, x)])]
pub fn trivial_ge(x: BV32) -> bool {
x <= x
}
#[flux::sig(fn (BV32[@x]) -> bool[bv_ugt(x, x)])]
pub fn trivial_gt(x: BV32) -> bool {
x < x
}
#[flux::sig(fn (BV32[@x], BV32[@y]) -> bool[
bv_ule(x, bv_int_to_bv32(10))
&&
bv_uge(y, bv_int_to_bv32(20))
&&
bv_ult(x, bv_int_to_bv32(11))
&&
bv_ugt(y, bv_int_to_bv32(21))
])]
pub fn real_example(x: BV32, y: BV32) -> bool {
x <= BV32::new(10) && y >= BV32::new(20) && x < BV32::new(11) && y > BV32::new(21)
}
#[flux_rs::sig(fn (BV32[@x], BV32[@y]) -> bool[true] requires bv_ult(x, y) && bv_ugt(x, bv_int_to_bv32(0x20)) && bv_ult(y, bv_int_to_bv32(0xFF)))]
pub fn lt_imp(x: BV32, y: BV32) -> bool {
x - BV32::new(0x20) < y + BV32::new(0x20)
}
#[flux_rs::sig(fn (BV32[@x], BV32[@y]) -> bool[true] requires bv_ule(x, y) && bv_uge(x, bv_int_to_bv32(0x20)) && bv_ule(y, bv_int_to_bv32(0xFF)))]
pub fn le_imp(x: BV32, y: BV32) -> bool {
x - BV32::new(0x20) <= y + BV32::new(0x20)
}
#[flux_rs::sig(fn (BV32[@x], BV32[@y]) -> bool[true] requires bv_ugt(x, y) && bv_ugt(y, bv_int_to_bv32(0x20)) && bv_ult(x, bv_int_to_bv32(0xFF)))]
pub fn gt_imp(x: BV32, y: BV32) -> bool {
x + BV32::new(0x20) > y - BV32::new(0x20)
}
#[flux_rs::sig(fn (BV32[@x], BV32[@y]) -> bool[true] requires bv_uge(x, y) && bv_uge(y, bv_int_to_bv32(0x20)) && bv_ule(x, bv_int_to_bv32(0xFF)))]
pub fn ge_imp(x: BV32, y: BV32) -> bool {
x + BV32::new(0x20) >= y - BV32::new(0x20)
}Specification functions
use flux_rs::{attrs::*, bitvec::BV32};
defs! {
fn is_pow2(x: bitvec<32>) -> bool {
(x > 0) && ((x & x - 1) == 0)
}
}
#[sig(fn(x: BV32) requires is_pow2(x) && 8 <= x ensures x % 8 == 0)]
fn theorem_pow2_octet(x: BV32) {}Extensions
// https://github.com/flux-rs/flux/issues/686
#[allow(dead_code)]
#[flux::sig(fn(x: bool[true]))]
pub fn assert(_x: bool) {}
#[flux::opaque]
#[flux::refined_by(v: bitvec<32>)]
struct Register {
inner: u32,
}
impl Register {
#[flux::sig(fn(u32[@n]) -> Register[bv_int_to_bv32(n)])]
#[flux::trusted]
fn new(v: u32) -> Self {
Register { inner: v }
}
#[flux::sig(fn(&Register[@n]) -> u64[bv_bv64_to_int(bv_zero_extend_32_to_64(n))])]
#[flux::trusted]
fn zero_extend(&self) -> u64 {
self.inner as u64
}
#[flux::sig(fn(&Register[@n]) -> u64[bv_bv64_to_int(bv_sign_extend_32_to_64(n))])]
#[flux::trusted]
fn sign_extend(&self) -> u64 {
self.inner as i32 as i64 as u64
}
}
pub fn test_bv_extensions() {
let r = Register::new(u32::MAX);
assert(r.zero_extend() == u32::MAX as u64);
assert(r.zero_extend() == 12); //~ ERROR refinement type
assert(r.sign_extend() == u64::MAX);
assert(r.sign_extend() == 12); //~ ERROR refinement type
}Bitvector Constants
#![flux::defs(
fn is_start(x:bitvec<32>) -> bool { x == START }
)]
#[flux::opaque]
#[flux::refined_by(val: bitvec<32>)]
pub struct BV32(u32);
impl BV32 {
#[flux::trusted]
#[flux::sig(fn (x:u32) -> BV32[bv_int_to_bv32(x)])]
const fn new(val: u32) -> Self {
BV32(val)
}
}
#[flux_rs::constant(bv_int_to_bv32(0x4567))]
pub const START: BV32 = BV32::new(0x4567);
#[flux_rs::sig(fn () -> BV32[START])]
pub fn test1() -> BV32 {
BV32::new(0x4567)
}
#[flux_rs::sig(fn () -> BV32{v: is_start(v)})]
pub fn test2() -> BV32 {
BV32::new(0x4567)
}
#[flux_rs::sig(fn () -> BV32{v: is_start(v)})]
pub fn test3() -> BV32 {
BV32::new(0x4568) //~ ERROR: refinement type
}char Literals
#[flux::sig(fn() -> char['a'])]
pub fn char00() -> char {
'a'
}
#[flux::sig(fn(c: char{v: 'a' <= v && v <= 'z'}) -> bool[true])]
pub fn lowercase(c: char) -> bool {
'c' == 'c'
}String Literals
#[flux::sig(fn (&str["cat"]))]
fn require_cat(_x: &str) {}
pub fn test_cat() {
require_cat("cat");
require_cat("dog"); //~ ERROR refinement type
}
#[flux::sig(fn (&str[@a], &{str[@b] | a == b}))]
fn require_eq(_x: &str, _y: &str) {}
pub fn test_eq() {
require_eq("a", "a");
require_eq("a", "b"); //~ ERROR refinement type
}Extern Specs
Sometimes you may want to refine a struct or function that outside your code. We refer to such a specification as an "extern spec," which is short for "external specification."
Currently, Flux supports extern specs for functions, structs, enums, traits and impls.
The support is a bit rudimentary. For example, multiple impls for a struct (such as &[T]
and [T]) may conflict, and extern specs for structs only support opaque refinements.
Extern specs are given using extern_spec attribute macro, which is provided
by the procedural macros package flux_rs.
use flux_rs::extern_spec;
The extern_spec is used to provide flux signatures for functions defined in external crates. See the specifications guide for more details.
Extern Functions
An example of refining an extern function can be found here.
To define an extern spec on a function, you need to do three things, which happen to correspond to each of the below lines.
#[extern_spec(std::mem)]
#[spec(fn(x: &mut T[@vx], y: &mut T[@vy]) ensures x: T[vy], y: T[vx])]
fn swap<T>(a: &mut T, b: &mut T);- Add the
#[extern_spec]attribute. This attribute optionally takes a path; in the above example, this isstd::mem. You can use this path to qualify the function. So in the above example, the function we are targeting has the full path ofstd::mem::swap. - Add a
#[spec(...)](or equivalently#[flux_rs::sig(...)]) attribute, which is required for any extern spec on a function. This signature behaves as if the#[flux_rs::trusted]attribute was added, because we cannot actually check the implementation. Instead, flux just verifies some simple things, like that the function arguments have compatible types. - Write a function stub whose rust signature matches the external function.
If you do the above, you can use std::mem::swap as if it were refined by the
above type.
Here are two examples:
pub fn test_swap() {
let mut x = 5;
let mut y = 10;
swap(&mut x, &mut y); // actually calls `std::mem::swap`
assert(x == 10); // verified by flux
assert(y == 5); // verified by flux
assert(y == 10); //~ ERROR refinement type
}use std::slice::from_ref;
use flux_attrs::extern_spec;
#[extern_spec]
#[flux::sig(fn(&T) -> &[T][1])]
fn from_ref<T>(s: &T) -> &[T];
#[flux::sig(fn(&i32) -> &[i32]{n: n > 0})]
pub fn test(x: &i32) -> &[i32] {
from_ref(x)
}Options
use flux_attrs::*;
#[extern_spec]
#[refined_by(is_some: bool)]
enum Option<T> {
#[variant(Option<T>[false])]
None,
#[variant((T) -> Option<T>[true])]
Some(T),
}
#[extern_spec]
impl<T> Option<T> {
#[sig(fn(&Self[@b]) -> bool[b])]
const fn is_some(&self) -> bool;
#[sig(fn(&Self[@b]) -> bool[!b])]
const fn is_none(&self) -> bool;
#[no_panic]
#[sig(fn(Option<T>[true]) -> T)]
const fn unwrap(self) -> T;
/// Core impl: https://github.com/rust-lang/rust/blob/c871d09d1cc32a649f4c5177bb819646260ed120/library/core/src/option.rs#L957
#[no_panic]
#[spec(fn(Option<T>[true], &str) -> T)]
const fn expect(self, msg: &str) -> T;
/// Core impl: https://github.com/rust-lang/rust/blob/c871d09d1cc32a649f4c5177bb819646260ed120/library/core/src/option.rs#L1025
#[no_panic]
#[spec(fn(Option<T>[@b], T) -> T)]
fn unwrap_or(self, default: T) -> T;
/// Core impl: https://github.com/rust-lang/rust/blob/c871d09d1cc32a649f4c5177bb819646260ed120/library/core/src/option.rs#L1044
#[flux_rs::no_panic_if(F::no_panic())]
#[spec(fn(Option<T>[@b], F) -> T where F: FnOnce() -> T)]
fn unwrap_or_else<F: FnOnce() -> T>(self, f: F) -> T;
#[sig(fn(&Self[@b]) -> Option<&T>[b])]
fn as_ref(&self) -> Option<&T>;
#[sig(fn(&mut Self[@b]) -> Option<&mut T>[b])]
fn as_mut(&mut self) -> Option<&mut T>;
#[sig(fn(&Self[@b]) -> &[T][if b { 1 } else { 0 }])]
fn as_slice(&self) -> &[T];
#[sig(fn(&mut Self[@b]) -> &mut [T][if b { 1 } else { 0 }])]
fn as_mut_slice(&mut self) -> &mut [T];
/// Core impl: https://github.com/rust-lang/rust/blob/c871d09d1cc32a649f4c5177bb819646260ed120/library/core/src/option.rs#L1465
#[no_panic]
#[spec(fn(Option<T>[@a], Option<U>[@b]) -> Option<U>[a && b])]
fn and<U>(self, optb: Option<U>) -> Option<U>;
/// Core impl: https://github.com/rust-lang/rust/blob/c871d09d1cc32a649f4c5177bb819646260ed120/library/core/src/option.rs#L1581
#[no_panic]
#[spec(fn(Option<T>[@a], Option<T>[@b]) -> Option<T>[a || b])]
fn or(self, optb: Option<T>) -> Option<T>;
/// Core impl: https://github.com/rust-lang/rust/blob/c6a955468b025dbe3d1de3e8f3e30496d1fb7f40/library/core/src/option.rs#L1309
#[no_panic]
#[spec(fn(Option<T>[@b], E) -> Result<T, E>[b])]
fn ok_or<E>(self, err: E) -> Result<T, E>;
/// Core impl: https://github.com/rust-lang/rust/blob/c6a955468b025dbe3d1de3e8f3e30496d1fb7f40/library/core/src/option.rs#L1334
#[flux_rs::no_panic_if(F::no_panic())]
#[spec(fn(Option<T>[@b], F) -> Result<T, E>[b] where F: FnOnce() -> E)]
fn ok_or_else<E, F: FnOnce() -> E>(self, err: F) -> Result<T, E>;
/// Core impl: https://github.com/rust-lang/rust/blob/c6a955468b025dbe3d1de3e8f3e30496d1fb7f40/library/core/src/option.rs#L1504
#[flux_rs::no_panic_if(F::no_panic())]
#[spec(fn(Option<T>[@b], F) -> Option<U>{s: s => b} where F: FnOnce(T) -> Option<U>)]
fn and_then<U, F: FnOnce(T) -> Option<U>>(self, f: F) -> Option<U>;
/// Core impl: https://github.com/rust-lang/rust/blob/c6a955468b025dbe3d1de3e8f3e30496d1fb7f40/library/core/src/option.rs#L1783
#[no_panic]
#[spec(fn(self: &mut Option<T>[@b]) -> Option<T>[b]
ensures self: Option<T>[false])]
const fn take(&mut self) -> Option<T>;
/// Core impl: https://github.com/rust-lang/rust/blob/c6a955468b025dbe3d1de3e8f3e30496d1fb7f40/library/core/src/option.rs#L1841
#[no_panic]
#[spec(fn(self: &mut Option<T>[@b], T) -> Option<T>[b]
ensures self: Option<T>[true])]
const fn replace(&mut self, value: T) -> Option<T>;
/// Core impl: https://github.com/rust-lang/rust/blob/c871d09d1cc32a649f4c5177bb819646260ed120/library/core/src/option.rs#L1160
#[flux_rs::no_panic_if(F::no_panic())]
#[spec(fn(Option<T>[@b], F) -> Option<U>[b] where F: FnOnce(T) -> U)]
fn map<U, F: FnOnce(T) -> U>(self, f: F) -> Option<U>;
/// Core impl: https://github.com/rust-lang/rust/blob/c871d09d1cc32a649f4c5177bb819646260ed120/library/core/src/option.rs#L1224
#[flux_rs::no_panic_if(F::no_panic())]
#[spec(fn(Option<T>[@b], U, F) -> U where F: FnOnce(T) -> U)]
fn map_or<U, F: FnOnce(T) -> U>(self, default: U, f: F) -> U;
}use flux_rs::{assert, attrs::*};
extern crate flux_core;
#[flux::trusted]
#[spec(fn(i32{v: false}) -> T)]
pub fn never<T>(_: i32) -> T {
loop {}
}
#[spec(fn(x:Option<T>[true]) -> T)]
pub fn my_unwrap<T>(x: Option<T>) -> T {
match x {
Option::Some(v) => v,
Option::None => never(0),
}
}
#[spec(fn(T) -> Option<T>[true])]
fn my_some<T>(x: T) -> Option<T> {
Option::Some(x)
}
pub fn test1() {
let x = my_some(42);
let y = my_unwrap(x);
assert(y == 42);
}
pub fn test3() {
let x = Option::Some(42);
let y = my_unwrap(x);
assert(y == 42);
}
pub fn test_opt_specs() {
let a = Some(42);
assert(a.is_some());
let b: Option<i32> = None;
assert(b.is_none());
let c = a.unwrap();
assert(c == 42);
}
#[spec(fn (numerator: u32, denominator: u32) -> Option<u32[numerator / denominator]>[denominator != 0])]
pub fn safe_div(numerator: u32, denominator: u32) -> Option<u32> {
if denominator == 0 { None } else { Some(numerator / denominator) }
}
pub fn test_safe_div() {
let res = safe_div(42, 2).unwrap();
assert(res == 21);
}Vec
use std::{
alloc::{Allocator, Global},
ops::{Deref, DerefMut, Index, IndexMut},
slice::SliceIndex,
};
use flux_attrs::*;
//---------------------------------------------------------------------------------------
#[extern_spec]
#[refined_by(len: int)]
#[invariant(0 <= len)]
struct Vec<T, A: Allocator = Global>;
//---------------------------------------------------------------------------------------
#[extern_spec]
impl<T> Vec<T> {
#[flux::sig(fn() -> Vec<T>[0])]
fn new() -> Vec<T>;
}
#[extern_spec]
impl<T, A: Allocator> Vec<T, A> {
#[spec(fn(self: &mut Vec<T, A>[@n], T) ensures self: Vec<T, A>[n+1])]
fn push(v: &mut Vec<T, A>, value: T);
#[spec(fn(&Vec<T, A>[@n]) -> usize[n])]
fn len(v: &Vec<T, A>) -> usize;
#[spec(fn(self: &mut Vec<T, A>[@n]) -> Option<T>[n > 0] ensures self: Vec<T, A>[if n > 0 { n-1 } else { 0 }])]
fn pop(&mut self) -> Option<T>;
#[spec(fn(self: &Vec<T, A>[@n]) -> bool[n == 0])]
fn is_empty(&self) -> bool;
}
#[extern_spec]
impl<T: Clone, A: Allocator + Clone> Clone for Vec<T, A> {
#[spec(fn(self: &Vec<T, A>[@n]) -> Vec<T, A>[n])]
fn clone(&self) -> Vec<T, A>;
}
//---------------------------------------------------------------------------------------
#[extern_spec]
impl<T, I: SliceIndex<[T]>, A: Allocator> Index<I> for Vec<T, A> {
#[assume_parametric(T)]
#[spec(fn(&Vec<T, A>[@len], {I[@idx] | <I as SliceIndex<[T]>>::in_bounds(idx, len)}) -> _)]
fn index(z: &Vec<T, A>, index: I) -> &<I as SliceIndex<[T]>>::Output;
}
#[extern_spec]
impl<T, I: SliceIndex<[T]>, A: Allocator> IndexMut<I> for Vec<T, A> {
#[assume_parametric(T)]
#[spec(fn(&mut Vec<T,A>[@len], {I[@idx] | <I as SliceIndex<[T]>>::in_bounds(idx, len)}) -> _)]
fn index_mut(z: &mut Vec<T, A>, index: I) -> &mut <I as SliceIndex<[T]>>::Output;
}
//---------------------------------------------------------------------------------------
#[extern_spec]
impl<'a, T, A: Allocator> IntoIterator for &'a Vec<T, A> {
#[spec(fn (&Vec<T, A>[@n]) -> <&Vec<T, A> as IntoIterator>::IntoIter[0,n])]
fn into_iter(v: &'a Vec<T, A>) -> <&'a Vec<T, A> as IntoIterator>::IntoIter;
}
#[extern_spec]
#[assoc(fn with_size(self: Self, n:int) -> bool { self.len == n })]
impl<T> FromIterator<T> for Vec<T> {}
// ---------------------------------------------------------------------------------------
#[extern_spec(std::vec)]
#[assoc(fn as_deref(v: Self, target: int) -> bool { v.len == target })]
impl<T, A: Allocator> Deref for Vec<T, A> {
#[sig(fn(self: &Self[@v]) -> &[T][v])]
fn deref(&self) -> &[T];
}
#[extern_spec(std::vec)]
impl<T, A: Allocator> DerefMut for Vec<T, A> {
#[sig(fn(self: &mut Self[@v]) -> &mut [T][v])]
fn deref_mut(&mut self) -> &mut [T];
}Extern Structs
Here is an example of refining an extern struct
use flux_attrs::extern_spec;
#[extern_spec(std::string)]
#[flux::refined_by(len: int)]
struct String;
#[flux::sig(fn(String[@n]) requires n == 3)]
fn expect_string_len_3(s: String) {}
#[flux::sig(fn(String[2]))]
fn test_string_len_2(s: String) {
expect_string_len_3(s); //~ ERROR refinement type
}Here's a longer example of refining an extern struct as well as an impl
use flux_attrs::extern_spec;
#[extern_spec]
#[flux::refined_by(len: int)]
struct String;
#[extern_spec]
impl String {
#[flux::sig(fn() -> String[0])]
fn new() -> String;
#[flux::sig(fn(&String[@n]) -> usize[n])]
fn len(s: &String) -> usize;
#[flux::sig(fn(&String[@n]) -> bool[n == 0])]
fn is_empty(s: &String) -> bool;
#[flux::sig(fn(s: &mut String[@n], char) ensures s: String[n+1])]
fn push(s: &mut String, c: char);
#[flux::sig(fn(s: &mut String[@n]) -> Option<char>
requires n > 0
ensures s: String[n-1])]
fn pop(s: &mut String) -> Option<char>;
#[flux::sig(fn(&String[@n]) -> &[u8][n])]
fn as_bytes(s: &String) -> &[u8];
}
#[extern_spec]
impl<T> [T] {
#[flux::sig(fn(&[T][@n]) -> usize[n])]
fn len(v: &[T]) -> usize;
#[flux::sig(fn(&[T][@n]) -> bool[n == 0])]
fn is_empty(v: &[T]) -> bool;
}
#[flux::sig(fn(bool[@b]) requires b)]
pub fn assert_true(_: bool) {}
pub fn test_string() {
let mut s = String::new();
assert_true(s.is_empty());
assert_true(s.as_bytes().is_empty());
s.push('h');
s.push('i');
assert_true(s.len() == 2);
s.pop();
assert_true(s.len() == 1);
s.pop();
assert_true(s.is_empty());
assert_true(s.as_bytes().is_empty());
}The syntax for an extern spec on a struct is very similar to that for a function. Once again, each line in the example happens to correspond to a step.
#[extern_spec(std::string)]
#[flux_rs::refined_by(len: int)]
struct String;
- Add the
#[extern_spec]attribute. This attribute optionally takes a path; in the above example, this isstd::string. You can use this path to qualify the function. So in the above example, the struct we are targeting has the full path ofstd::string::String. - Add a
#[flux_rs::refined_by(...)]attribute. This is required for any extern spec on a struct. Right now these attributes behave as if they were opaque (#[flux_rs::opaque]), although we may support non-opaque extern structs. - Write a stub for the extern struct.
If you do the above, you can use std::string::String as if it were refined by
an integer index.
The syntax for an extern impl is a little different than that for functions or structs.
#[extern_spec(std::string)]
impl String {
#[flux_rs::sig(fn() -> String[0])]
fn new() -> String;
#[flux_rs::sig(fn(&String[@n]) -> usize[n])]
fn len(s: &String) -> usize;
}
- You still need to add the
#[extern_spec]attribute, with the same optional argument of the path as above. - You need to write out the
implblock for the struct you want to refine. This struct does not need an extern spec, since by refining theimplyou're only refining its methods. - Write an extern spec for each function you wish to refine (this may be a
subset). This is written just like a function extern spec with the caveat
that the
selfparameter is not presently supported. So for example, instead of writingfn len(&self) -> usize;, you need to writefn len(s: &String) -> usize;.
If you do the above, you can use the above methods ofstd::string::String as if
they were refined.
// Testing we can add external specs to "transparent" structs.
use flux_attrs::extern_spec;
#[extern_spec(std::ops)]
#[refined_by(start: Idx, end: Idx)]
struct Range<Idx> {
#[field(Idx[start])]
start: Idx,
#[field(Idx[end])]
end: Idx,
}
#[extern_spec(std::ops)]
impl<Idx: PartialOrd<Idx>> Range<Idx> {
// This specification is actually unsound for `Idx`s where the `PartialOrd` implementation doesn't
// match the logical `<`.
#[sig(fn(&Range<Idx>[@r]) -> bool[!(r.start < r.end)])]
fn is_empty(&self) -> bool;
}
#[flux::sig(fn(bool[true]))]
fn assert(_: bool) {}
fn test00() {
let r = 0..1;
assert(!r.is_empty());
}// Extern spec of a type with a lifetime
use std::slice::Iter;
use flux_attrs::*;
#[extern_spec]
#[refined_by(len: int)]
struct Iter<'a, T>;
#[extern_spec]
impl<'a, T> Iter<'a, T> {
#[spec(fn as_slice(&Iter<T>[@n]) -> &[T][n])]
fn as_slice(v: &Iter<'a, T>) -> &'a [T];
}
#[extern_spec]
impl<T> [T] {
#[spec(fn iter(&[T][@n]) -> Iter<T>[n])]
fn iter(v: &[T]) -> Iter<'_, T>;
}
#[spec(fn test00(x: &[i32][@n]) -> &[i32][n])]
fn test00(x: &[i32]) -> &[i32] {
x.iter().as_slice()
}Extern Impls
use flux_attrs::extern_spec;
#[extern_spec]
#[flux::refined_by(len: int)]
struct String;
#[extern_spec]
impl String {
#[flux::sig(fn() -> String[0])]
fn new() -> String;
#[flux::sig(fn(&String[@n]) -> usize[n])]
fn len(s: &String) -> usize;
#[flux::sig(fn(&String[@n]) -> bool[n == 0])]
fn is_empty(s: &String) -> bool;
#[flux::sig(fn(s: &mut String[@n], char) ensures s: String[n+1])]
fn push(s: &mut String, c: char);
#[flux::sig(fn(s: &mut String[@n]) -> Option<char>
requires n > 0
ensures s: String[n-1])]
fn pop(s: &mut String) -> Option<char>;
#[flux::sig(fn(&String[@n]) -> &[u8][n])]
fn as_bytes(s: &String) -> &[u8];
}
#[extern_spec]
impl<T> [T] {
#[flux::sig(fn(&[T][@n]) -> usize[n])]
fn len(v: &[T]) -> usize;
#[flux::sig(fn(&[T][@n]) -> bool[n == 0])]
fn is_empty(v: &[T]) -> bool;
}
#[flux::sig(fn(bool[@b]) requires b)]
pub fn assert_true(_: bool) {}
pub fn test_string() {
let mut s = String::new();
assert_true(s.is_empty());
assert_true(s.as_bytes().is_empty());
s.push('h');
s.push('i');
assert_true(s.len() == 2);
s.pop();
assert_true(s.len() == 1);
s.pop();
assert_true(s.is_empty());
assert_true(s.as_bytes().is_empty());
}//@aux-build:extern_spec_impl01_aux.rs
extern crate extern_spec_impl01_aux;
use extern_spec_impl01_aux::MyTrait;
use flux_attrs::extern_spec;
#[extern_spec]
impl<T> MyTrait for Vec<T> {
#[flux::sig(fn() -> i32[10])]
fn foo() -> i32;
}
#[flux::sig(fn () -> i32[10])]
pub fn test_ok() -> i32 {
<Vec<i32> as MyTrait>::foo()
}Extern Traits
use flux_attrs::*;
#[extern_spec(std::cmp)]
#[assoc(fn eq_rel(lhs: Self, rhs: Rhs) -> bool)]
trait PartialEq<Rhs> {
#[sig(fn(&Self[@lhs], &Rhs[@rhs]) -> bool[<Self as PartialEq<Rhs>>::eq_rel(lhs, rhs)])]
fn eq(&self, other: &Rhs) -> bool;
}
#[refined_by(n: int)]
struct MyInt(#[field(i32[n])] i32);
#[assoc(fn eq_rel(lhs: MyInt, rhs: MyInt) -> bool { lhs == rhs })]
impl PartialEq for MyInt {
#[sig(fn(&Self[@lhs], &MyInt[@rhs]) -> bool[<MyInt as PartialEq<MyInt>>::eq_rel(lhs, rhs)])]
fn eq(&self, other: &MyInt) -> bool {
self.0 == other.0
}
}
#[sig(fn(x: T, y: T) -> bool[<T as PartialEq<T>>::eq_rel(x, y)])]
fn test00<T: PartialEq>(x: T, y: T) -> bool {
x == y
}
#[sig(fn(x: MyInt, y: MyInt) -> bool[x == y])]
fn test01(x: MyInt, y: MyInt) -> bool {
test00(x, y)
}for loops with range i..j
To see how flux handles for i in 0..n style loops:
#![feature(step_trait)]
#![allow(unused)]
extern crate flux_core;
#[flux_rs::sig(fn (bool[true]))]
fn assert(b: bool) {}
fn donald() {
let n: i32 = 10;
let mut thing = 0..n;
let a = thing.next().unwrap();
assert(a == 0);
let b = thing.next().unwrap();
assert(b == 1);
let c = thing.next().unwrap();
assert(c == 2);
}
#[flux_rs::sig(fn (n:i32{n == 99}))]
fn goofy(n: i32) {
let mut thing = 0..n;
let a0 = thing.end;
assert(a0 == n);
while let Some(i) = thing.next() {
assert(0 <= i);
assert(i < n);
}
}
#[flux_rs::sig(fn (n:i32{n == 99}))]
fn mickey(n: i32) {
for i in 0..n {
assert(0 <= i);
assert(i < n);
}
}
#[flux_rs::trusted]
fn cond() -> bool {
todo!()
}
fn test(len: i32) {
if len >= 0 {
let mut del = 0;
for i in 0..len {
assert(del <= i);
if cond() {
del += 1;
}
}
assert(del <= len)
}
}Associated Refinements
Basic
#![allow(dead_code)]
use flux_attrs::*;
trait MyTrait {
#![reft(fn f(x: int) -> int)]
//
}
struct Add1;
impl MyTrait for Add1 {
#![reft(fn f(x: int) -> int { x + 1 })]
//
}
#[sig(fn(x: i32{v: v == <Add1 as MyTrait>::f(0) }))]
fn test00(_x: i32) {}
fn test01() {
test00(1);
}Check Subtyping at Impl
// test that implementations with extra const generics work as expected
use flux_attrs::*;
#[reft(fn p(x: int) -> bool)]
trait MyTrait {
#[sig(fn() -> i32{ v: <Self as MyTrait>::p(v) })]
fn method() -> i32;
}
struct MyStruct<const N: i32>;
// This implementation requires proving `x == N => x >= N`
#[reft(fn p(x: int) -> bool { x >= N })]
impl<const N: i32> MyTrait for MyStruct<N> {
#[sig(fn() -> i32{v: v == N})]
fn method() -> i32 {
N
}
}Default
use flux_attrs::*;
pub trait MyTrait {
#![reft(fn f(x: int) -> int { x + 1 })]
//
}
// -----------------------------------------------------------------------------
pub struct Add1;
// Use the "default" assoc reft for Add1
impl MyTrait for Add1 {}
#[flux::sig(fn() -> i32{v: v == <Add1 as MyTrait>::f(0)})]
pub fn test1_ok() -> i32 {
1
}
#[flux::sig(fn() -> i32{v: v == <Add1 as MyTrait>::f(0)})]
pub fn test1_fail() -> i32 {
99 //~ ERROR: refinement type error
}
// -----------------------------------------------------------------------------
pub struct Add2;
// Specify a custom assoc reft for Add2
impl MyTrait for Add2 {
#![reft(fn f(x: int) -> int { x + 2 })]
//
}
#[flux::sig(fn() -> i32{v: v == <Add2 as MyTrait>::f(0)})]
pub fn test2() -> i32 {
2
}Use in Extern Spec
use flux_attrs::*;
#[extern_spec(std::cmp)]
#[assoc(fn eq_rel(lhs: Self, rhs: Rhs) -> bool)]
trait PartialEq<Rhs> {
#[sig(fn(&Self[@lhs], &Rhs[@rhs]) -> bool[<Self as PartialEq<Rhs>>::eq_rel(lhs, rhs)])]
fn eq(&self, other: &Rhs) -> bool;
}
#[refined_by(n: int)]
struct MyInt(#[field(i32[n])] i32);
#[assoc(fn eq_rel(lhs: MyInt, rhs: MyInt) -> bool { lhs == rhs })]
impl PartialEq for MyInt {
#[sig(fn(&Self[@lhs], &MyInt[@rhs]) -> bool[<MyInt as PartialEq<MyInt>>::eq_rel(lhs, rhs)])]
fn eq(&self, other: &MyInt) -> bool {
self.0 == other.0
}
}
#[sig(fn(x: T, y: T) -> bool[<T as PartialEq<T>>::eq_rel(x, y)])]
fn test00<T: PartialEq>(x: T, y: T) -> bool {
x == y
}
#[sig(fn(x: MyInt, y: MyInt) -> bool[x == y])]
fn test01(x: MyInt, y: MyInt) -> bool {
test00(x, y)
}use std::{
alloc::{Allocator, Global},
ops::{Deref, DerefMut, Index, IndexMut},
slice::SliceIndex,
};
use flux_attrs::*;
//---------------------------------------------------------------------------------------
#[extern_spec]
#[refined_by(len: int)]
#[invariant(0 <= len)]
struct Vec<T, A: Allocator = Global>;
//---------------------------------------------------------------------------------------
#[extern_spec]
impl<T> Vec<T> {
#[flux::sig(fn() -> Vec<T>[0])]
fn new() -> Vec<T>;
}
#[extern_spec]
impl<T, A: Allocator> Vec<T, A> {
#[spec(fn(self: &mut Vec<T, A>[@n], T) ensures self: Vec<T, A>[n+1])]
fn push(v: &mut Vec<T, A>, value: T);
#[spec(fn(&Vec<T, A>[@n]) -> usize[n])]
fn len(v: &Vec<T, A>) -> usize;
#[spec(fn(self: &mut Vec<T, A>[@n]) -> Option<T>[n > 0] ensures self: Vec<T, A>[if n > 0 { n-1 } else { 0 }])]
fn pop(&mut self) -> Option<T>;
#[spec(fn(self: &Vec<T, A>[@n]) -> bool[n == 0])]
fn is_empty(&self) -> bool;
}
#[extern_spec]
impl<T: Clone, A: Allocator + Clone> Clone for Vec<T, A> {
#[spec(fn(self: &Vec<T, A>[@n]) -> Vec<T, A>[n])]
fn clone(&self) -> Vec<T, A>;
}
//---------------------------------------------------------------------------------------
#[extern_spec]
impl<T, I: SliceIndex<[T]>, A: Allocator> Index<I> for Vec<T, A> {
#[assume_parametric(T)]
#[spec(fn(&Vec<T, A>[@len], {I[@idx] | <I as SliceIndex<[T]>>::in_bounds(idx, len)}) -> _)]
fn index(z: &Vec<T, A>, index: I) -> &<I as SliceIndex<[T]>>::Output;
}
#[extern_spec]
impl<T, I: SliceIndex<[T]>, A: Allocator> IndexMut<I> for Vec<T, A> {
#[assume_parametric(T)]
#[spec(fn(&mut Vec<T,A>[@len], {I[@idx] | <I as SliceIndex<[T]>>::in_bounds(idx, len)}) -> _)]
fn index_mut(z: &mut Vec<T, A>, index: I) -> &mut <I as SliceIndex<[T]>>::Output;
}
//---------------------------------------------------------------------------------------
#[extern_spec]
impl<'a, T, A: Allocator> IntoIterator for &'a Vec<T, A> {
#[spec(fn (&Vec<T, A>[@n]) -> <&Vec<T, A> as IntoIterator>::IntoIter[0,n])]
fn into_iter(v: &'a Vec<T, A>) -> <&'a Vec<T, A> as IntoIterator>::IntoIter;
}
#[extern_spec]
#[assoc(fn with_size(self: Self, n:int) -> bool { self.len == n })]
impl<T> FromIterator<T> for Vec<T> {}
// ---------------------------------------------------------------------------------------
#[extern_spec(std::vec)]
#[assoc(fn as_deref(v: Self, target: int) -> bool { v.len == target })]
impl<T, A: Allocator> Deref for Vec<T, A> {
#[sig(fn(self: &Self[@v]) -> &[T][v])]
fn deref(&self) -> &[T];
}
#[extern_spec(std::vec)]
impl<T, A: Allocator> DerefMut for Vec<T, A> {
#[sig(fn(self: &mut Self[@v]) -> &mut [T][v])]
fn deref_mut(&mut self) -> &mut [T];
}mod adapters;
#[cfg(flux)]
mod range;
mod traits;#![allow(unused)]
#![feature(allocator_api)]
use std::{iter::Enumerate, slice::Iter};
extern crate flux_alloc;
extern crate flux_core;
#[flux::sig(fn(bool[true]))]
pub fn assert(_b: bool) {}
// Tests
#[flux::sig(fn(slice: &[u8]{n: n > 0}))]
fn test_iter1(slice: &[u8]) {
let mut iter = slice.iter();
let next = iter.next();
assert(next.is_some());
}
#[flux::sig(fn(slice: &[u8]{n: n > 1}))]
fn test_enumerate1(slice: &[u8]) {
assert(slice.len() > 0);
let mut enumer = slice.iter().enumerate();
let next = enumer.next();
assert(next.is_some());
let (idx, _) = next.unwrap();
assert(idx == 0);
let next_next = enumer.next();
assert(next_next.is_some());
let (idx, _) = next_next.unwrap();
assert(idx == 1);
}
#[flux::sig(fn(&[usize][1]) )]
pub fn test_enumer2(slice: &[usize]) {
assert(slice.len() == 1);
let mut enumer = slice.iter().enumerate();
let next = enumer.next();
assert(next.is_some());
let next_next = enumer.next();
assert(next_next.is_none())
}
#[flux::sig(fn(&[usize][@n]) )]
pub fn test_enumer3(slice: &[usize]) {
let mut e = slice.iter().enumerate();
while let Some((idx, _)) = e.next() {
assert(idx < slice.len())
}
}
#[flux::sig(fn(&[usize][@n]) )]
pub fn test_enumer4(slice: &[usize]) {
for (idx, _) in slice.iter().enumerate() {
assert(idx < slice.len())
}
}Associated Types
use flux_attrs::*;
trait MyTrait {
#![reft(fn f(x: int) -> int)]
//
}
struct Add1;
#[assoc(fn f(x: int) -> int { x + 1 })]
impl MyTrait for Add1 {}
#[sig(fn(x: i32{v: v == <Add1 as MyTrait>::f(0) }))]
fn test00(x: i32) {}
fn test01() {
test00(0); //~ ERROR refinement type error
}// Testing that we properly map generics in trait's default associated refinement
// body into the impl.
use flux_attrs::*;
trait MyTrait {
#![reft(fn p(x: Self) -> bool { true })]
#[sig(fn(&Self{v: <Self as MyTrait>::p(v)}))]
fn method(&self);
}
impl MyTrait for i32 {
#[sig(fn(&Self{v: <Self as MyTrait>::p(v)}))]
fn method(&self) {}
}
impl<T> MyTrait for S<T> {
#[sig(fn(&Self{v: <Self as MyTrait>::p(v)}))]
fn method(&self) {}
}
struct S<T> {
f: T,
}Refined Associated Types
use flux_attrs::*;
#[assoc(fn can_fit(self: Self, animal: Self::Animal) -> bool)]
trait Barn {
type Animal;
#[sig(fn(self: &mut Self[@barn], animal: Self::Animal{ <Self as Barn>::can_fit(barn, animal) }))]
fn put_animal_in_house(&mut self, animal: Self::Animal);
}
#[refined_by(size: int)]
struct Horse {
#[field(i32[size])]
size: i32,
}
#[refined_by(max_size: int)]
struct HorseBarn {
#[field(i32[max_size])]
max_size: i32,
}
#[assoc(fn can_fit(self: HorseBarn, horse: Horse) -> bool { horse.size <= self.max_size })]
impl Barn for HorseBarn {
type Animal = Horse;
#[trusted]
#[sig(fn(self: &mut Self[@barn], horse: Horse { horse.size <= barn.max_size}))]
fn put_animal_in_house(&mut self, horse: Horse) {}
}
fn test00() {
let mut barn = HorseBarn { max_size: 20 };
let horse = Horse { size: 10 };
barn.put_animal_in_house(horse);
}Checking Overflows
You can switch on overflow checking
- globally with a flag or
- locally with an attribute as shown below
const MAX: u32 = std::u32::MAX;
// Error on this as it may overflow
#[flux::opts(check_overflow = "strict")]
#[flux::sig(fn (u32[@x], u32[@y], u32[@z]) -> u32[x + y + z] requires x + y + z <= MAX)]
fn add_three(x: u32, y: u32, z: u32) -> u32 {
x + y + z
}#[flux::opts(check_overflow = "strict")]
mod my_mod {
const MAX: u32 = std::u32::MAX;
#[flux::sig(fn(u32[@x], u32[@y]) -> u32[x + y] requires x + y <= MAX)]
fn add(x: u32, y: u32) -> u32 {
x + y
}
#[flux::sig(fn(u32[@x]) -> u32[x + 2] requires x + 2 <= MAX)]
fn add2(x: u32) -> u32 {
x + 2
}
}const MAX: u32 = std::u32::MAX;
#[flux_rs::refined_by(inner: int)]
struct MyStruct {
#[field(u32[inner])]
inner: u32,
}
impl MyStruct {
fn add1(&self) -> u32 {
self.inner + 1
}
// Error as this may overflow
#[flux::opts(check_overflow = "strict")]
#[flux::sig(fn (&MyStruct[@inner]) -> u32[inner + 2] requires inner + 2 <= MAX)]
fn add2(&self) -> u32 {
self.inner + 2
}
}const MAX: u32 = std::u32::MAX;
struct MyStruct {
inner: u32,
}
#[flux::opts(check_overflow = "strict")]
trait MyTrait {
#[flux::sig(fn(u32[@x], { u32[@y] | x + y <= MAX }) -> u32[x + y] )]
fn add(x: u32, y: u32) -> u32;
}
impl MyTrait for MyStruct {
#[flux::sig(fn(u32[@x], { u32[@y] | x + y <= MAX }) -> u32[x + y] )]
fn add(x: u32, y: u32) -> u32 {
x + y
}
}Extensible Properties for Primitive Ops
You can provide properties to be used when doing computations with
primitive operations like << or >>.
Given a primop op with signature (t1,...,tn) -> t we define
a refined type for op expressed as a [RuleMatcher]
op :: (x1: t1, ..., xn: tn) -> { t[op_val[op](x1,...,xn)] | op_rel[x1,...,xn] }that is, using two uninterpreted functions op_val and op_rel that respectively denote
- The value of the primop, and
- Some invariant relation that holds for the primop.
The latter can be extended by the user via a property definition,
which allows us to customize primops like << with extra "facts"
or lemmas. See tests/tests/pos/surface/primops00.rs for an example.
use flux_rs::{assert, attrs::*, defs};
defs! {
fn is_char(n: int) -> bool {
0 <= n && n <= 0x10FFFF
}
property ShiftByTwo[<<](x, y) {
[<<](x, 2) == 4*x
}
property ShiftRightByFour[>>](x, y) {
16 * [>>](x, 4) == x
}
property MaskBy[&](x, y) {
[&](x, y) <= y
}
property XorSelfInverse[^](x, y) {
x == y => [^](x, y) == 0
}
property OrBy1[|](x, y) {
is_char(x) => is_char([|](x, 1))
}
}
pub fn test0() {
let x: usize = 1 << 2;
assert(x == 4);
}
pub fn test1() {
let x = 1;
let x = x << 2;
let x = x << 2;
assert(x == 16)
}
#[spec(fn (x: u32) -> u32[16*x])]
pub fn test2(x: u32) -> u32 {
let x = x << 2;
let x = x << 2;
x
}
#[spec(fn (byte: u8{byte <= 127}))]
pub fn test3(byte: u8) {
let tmp1 = byte >> 4;
let tmp2 = byte & 0xf;
assert(byte <= 127);
assert(tmp1 <= 0xf);
assert(tmp2 <= 0xf);
}
static POW10: [i32; 10] = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
pub fn test4(n: usize) -> i32 {
POW10[n & 7]
}
#[spec(fn(x: usize) -> usize[0])]
pub fn test5(x: usize) -> usize {
x ^ x
}
pub fn test6(c: char) {
let c = c as u32;
flux_rs::assert(c <= 0x10FFFF); // (0)
let c = c | 1;
flux_rs::assert(c <= 0x10FFFF); // (1)
}
#[spec(fn (b:bool) -> usize{v: v <= 7})]
pub fn test7(b: bool) -> usize {
let n: usize = 10;
let m = if b { n & 7 } else { 6 };
m
}Casting Sorts
You can convert refinements of different sorts -- e.g. int to char or int to bool --
using the cast internal function.
#![flux::defs {
fn is_ascii_digit(c: char) -> bool {
let i = cast(c);
48 <= i && i <= 57
}
fn is_ascii(c: char) -> bool {
let i = cast(c);
0 <= i && i <= 127
}
}]
use flux_rs::{assert, attrs::*};
// extern specs for is_ascii and is_ascii_digit
#[extern_spec]
impl char {
#[spec(fn (&Self[@c]) -> bool[is_ascii(c)])]
fn is_ascii(&self) -> bool;
#[spec(fn (&Self[@c]) -> bool[is_ascii_digit(c)])]
fn is_ascii_digit(&self) -> bool;
}
pub fn test_ok(x: char) {
if x.is_ascii_digit() {
assert(x.is_ascii())
}
}
#[spec(fn (char{v: '0' <= v && v <= '9'}))]
pub fn test_digit(x: char) {
assert(x.is_ascii_digit())
}Detached Specifications
Sometimes you may want to write specs for functions, structs, enums etc. but not directly attached to the function i.e. as an attribute of the definition, perhaps because you don't want to modify the original source file, or because the code for the function was derived or generated by a macro.
You can write detached specifications using the specs macro
as illustrated by the following
Function Types
#![flux::specs {
fn inc(n:i32) -> i32{v: n < v};
fn id(n:i32) -> i32[n];
}]
pub fn inc(n: i32) -> i32 {
n - 1 //~ ERROR refinement type
}
pub fn id(n: i32) -> i32 {
n
}Structs
use flux_rs::assert;
pub struct MyStruct {
x: usize,
y: usize,
}
pub fn mk_struct(x: usize, y: usize) -> MyStruct {
if x < y { MyStruct { x, y } } else { MyStruct { x: y, y: x } }
}
pub fn use_struct(s: MyStruct) {
assert(s.x <= s.y)
}
#[flux::specs {
#[refined_by(vx: int, vy: int)]
#[invariant(vx <= vy)]
struct MyStruct {
x: usize[vx],
y: usize[vy],
}
}]
const _: () = ();Enums
enum Nat {
Zero,
Succ(Box<Nat>),
}
fn zero() -> Nat {
Nat::Zero
}
fn succ(n: Nat) -> Nat {
Nat::Succ(Box::new(n))
}
fn from_usize(n: usize) -> Nat {
if n == 0 { zero() } else { succ(from_usize(n - 1)) }
}
#[flux::specs {
#[refined_by(n: int)]
#[invariant(0 <= n)]
enum Nat {
Zero -> Nat[0],
Succ(Box<Nat[@n]>) -> Nat[n+1],
}
fn zero() -> Nat[0];
fn succ(n:Nat) -> Nat[n+1];
fn from_usize(n:usize) -> Nat[n];
}]
const _: () = ();Traits
#![allow(dead_code)]
use flux_attrs::*;
trait MyTrait {
fn baz(&self) -> usize;
}
struct Add1;
impl MyTrait for Add1 {
fn baz(&self) -> usize {
1
}
}
#[spec(fn(x: i32{v: v == <Add1 as MyTrait>::f(0) }))]
fn test00(_x: i32) {}
fn test01() {
test00(1);
}
#[flux::specs {
trait MyTrait {
#[reft]
fn f(x: int) -> int;
fn baz(&Self) -> usize[Self::f(0)];
}
impl MyTrait for Add1 {
#[reft] fn f(x: int) -> int {
x + 1
}
fn baz(&Self) -> usize[1];
}
}]
const _: () = ();Inherent Impls
use flux_attrs::*;
pub enum Nat {
Zero,
Succ(Box<Nat>),
}
impl Nat {
fn zero() -> Self {
Nat::Zero
}
}
impl Nat {
fn succ(n: Self) -> Self {
Nat::Succ(Box::new(n))
}
}
// --------------------------------------------------------------------------------------
#[spec(fn () -> Nat[0])]
pub fn test_a() -> Nat {
Nat::zero()
}
#[spec(fn () -> Nat[3])]
pub fn test_b() -> Nat {
Nat::succ(Nat::succ(Nat::succ(Nat::zero())))
}
// --------------------------------------------------------------------------------------
#[flux::specs {
#[refined_by(n: int)]
#[invariant(0 <= n)]
enum Nat {
Zero -> Nat[0],
Succ(Box<Nat[@n]>) -> Nat[n + 1],
}
impl Nat {
fn zero() -> Nat[0];
}
impl Nat {
fn succ(n:Nat) -> Nat[n+1];
}
}]
const _: () = ();Trait Impls
Note the fully qualified name of the trait in the spec.
#![allow(unused)]
extern crate flux_core;
use flux_rs::{assert, attrs::*};
pub mod a {
pub mod b {
pub trait MyTrait {
fn gromp(&self) -> usize;
}
}
}
pub mod x {
pub mod y {
pub struct Thing<T> {
inner: T,
}
impl<T> Thing<T> {
pub fn new(inner: T) -> Self {
Thing { inner }
}
}
impl<T> crate::a::b::MyTrait for Thing<T> {
fn gromp(&self) -> usize {
42
}
}
}
}
// -------------------------------------------------------------------
mod test {
use crate::a::b::MyTrait;
#[flux_rs::spec(fn () -> usize[42])]
fn test() -> usize {
crate::x::y::Thing::new(true).gromp()
}
}
// -------------------------------------------------------------------
#[flux_rs::specs {
mod x {
mod y {
impl a::b::MyTrait for Thing<T> {
fn gromp(&Self) -> usize[42];
}
}
}
}]
const _: () = ();Include Patterns
You can include patterns to restrict flux to only check a subset of a codebase.
A def_id is checked if it matches any of the patterns.
cargo x run tests/tests/pos/detached/detach00.rs -- -Fdump-checker-trace -Fdump-constraint -Finclude=span:tests/tests/pos/detached/detach00.rs:13:1 -Finclude=def:id -Finclude=path/to/file.rs
Scraping Qualifiers
Sometimes it is useful to tell fixpoint to automatically "scrape" qualifiers from constraints etc. to synthesize solutions for constraints.
#![flux::opts(scrape_quals = "true")]
#[path = "../../lib/rvec.rs"]
mod rvec;
use rvec::RVec;
// test that the (fixpoint) `--scrape` mechanism suffices to get
// the qualifier needed for the loop invariant below.
#[flux::sig(fn(lo: usize, hi:usize{lo<=hi}) -> RVec<usize>[hi-lo] )]
pub fn range(lo: usize, hi: usize) -> RVec<usize> {
let mut i = lo;
let mut res = RVec::new();
while i < hi {
// inv: res.len() = i - lo
res.push(i);
i += 1;
}
res
}Invariant Macro
The invariant! macro can be used to simulate a restricted form of loop invariant,
by simultaneously specifying assertions and qualifiers that can be used to establish
that assertion.
use flux_rs::{attrs::*, macros::invariant};
#[spec(fn (n: usize) -> usize[n])]
pub fn test_with_qualifier(n: usize) -> usize {
let mut i = n;
let mut res = 0;
while i > 0 {
#[flux::defs{
invariant qualifier Auto(res: int) { res + i == n && i >= 99-99 && res >= 66 - 66 }
}]
const _: () = ();
i -= 1;
res += 1;
}
res
}
#[spec(fn (n: usize) -> usize[n])]
pub fn test(n: usize) -> usize {
let mut i = n;
let mut res = 0;
while i > 0 {
invariant!(res:int; res + i == n && i >= 99-99 && res >= 66 - 66);
i -= 1;
res += 1;
}
res
}-
#[flux_rs::ignore](resp.#[flux_rs::trusted]) is shorthand for#[flux_rs::ignore(yes)](resp.#[flux_rs::trusted(yes)]). ↩
Developer's Guide
Backtraces
You can use the usual RUST_BACKTRACE=1 environment variable to enable backtraces.
With the regular release build (cargo x install) you get some backtraces, but
the dev build, which you can install as shown below, gives more information e.g.
the source-spans of various calls in the backtrace.
$ cargo x install --profile dev
Regression Tests
You can run the various regression tests in the tests/pos and tests/neg directories using
cargo xtask test
This will build the flux binary and then run it against the entire test suite. You can optionally pass a filter to only run tests containing some substring. For example:
$ cargo xtask test impl_trait
Compiling xtask v0.1.0 (/path/to/flux/xtask)
Finished dev [unoptimized + debuginfo] target(s) in 0.29s
Running `target/debug/xtask test impl_trait`
$ cargo build
Finished dev [unoptimized + debuginfo] target(s) in 0.05s
$ cargo test -p tests -- --test-args impl_trait
Compiling fluxtests v0.1.0 (/path/to/flux/tests)
Finished test [unoptimized + debuginfo] target(s) in 0.62s
Running tests/compiletest.rs (target/debug/deps/compiletest-1241128f1f51caa4)
running 5 tests
test [ui] pos/surface/impl_trait04.rs ... ok
test [ui] pos/surface/impl_trait03.rs ... ok
test [ui] pos/surface/impl_trait01.rs ... ok
test [ui] pos/surface/impl_trait00.rs ... ok
test [ui] pos/surface/impl_trait02.rs ... ok
test result: ok. 5 passed; 0 failed; 0 ignored; 0 measured; 191 filtered out; finished in 0.10s
running 2 tests
test [compile-fail] neg/surface/impl_trait00.rs ... ok
test [compile-fail] neg/surface/impl_trait02.rs ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 207 filtered out; finished in 0.09s
Test Suites
The test suite is split into two tiers based on what the test requires at compile time.
Basic tests (tests/pos/ and tests/neg/) only require flux_attrs, the procedural macro
crate that provides Flux's surface syntax. Prefer writing tests here whenever possible.
A test belongs in the basic suite if it only uses Flux attributes directly, that is, it uses
flux_attrs::* (or #[flux::*]) without importing flux_rs, flux_core, or flux_alloc.
Dependency tests (tests/with_deps/pos/ and tests/with_deps/neg/) require the full set of
precompiled Flux libraries (flux_rs, flux_core, flux_alloc). Only place a test here when it
genuinely needs one of those libraries, for example, when testing extern specs for
standard-library types or behaviour that relies on the flux_rs prelude.
Testing Flux on a File
When working on Flux, you may want to test your changes by running it against a test file.
You can use cargo xtask run <input> to run Flux on a single input file.
The command will set appropriate flags to be able to use custom Flux attributes and macros,
plus some extra flags useful for debugging.
For example:
$ cat test.rs
#[flux::sig(fn(x: i32) -> i32[x + 1])]
fn add1(x: i32) -> i32 {
x + 1
}
$ cargo xtask run test.rs
The command will use a super set of the flags passed when running regression tests.
Thus, a common workflow is to identify a failing test and run it directly with cargo xtask run,
or alternatively copy it to a different file.
You may also find useful to create a directory in the root of the project and add it to
.git/info/exclude.
You can keep files there, outside of version control, and test Flux against them.
I have a directory called attic/ where I keep a file named playground.rs.
To run Flux on it, I do cargo xtask run attic/playground.rs.
Reporting locations where errors are emitted
When you use cargo xtask run you'll see that we report the location an error was emitted, e.g.,
error[FLUX]: refinement type error
--> attic/playground.rs:4:5
|
4 | 0
| ^ a postcondition cannot be proved
-Ztrack-diagnostics: created at crates/flux-refineck/src/lib.rs:114:15 <------- this
You can also pass -Ztrack-diagnostics=y to enable it if you are not using cargo xtask run
Macro expansion
For example if you have code like in path/to/file.rs
#![allow(unused)] fn main() { #[extern_spec] #[flux::refined_by(elems: Set<T>)] struct HashSet<T, S = RandomState>; }
and you want to see what the extern_spec macro expands it out to, then run
cargo x run -- -Zunpretty=expanded path/to/file.rs
Or you can run the xtask command directly
cargo x expand path/to/file.rs
Examining the MIR
You can use the -Zdump-mir flag to dump the MIR at various stages of compilation.
For example,
$ cargo x run path/to/test.rs -- -Zdump-mir=renumber
or
$ cargo x run path/to/test.rs -- -Zdump-mir=ghost
will stash the MIR for those relevant stages in the mir_dump directory.
You can then look at the <fn-name>.ghost.mir to see the MIR that Flux is checking.
Reporting and dealing with bugs
As Flux is under active development, there are many aspects of Rust that Flux does not yet support, are only partially implemented, or where the implementation may contain bugs. These issues typically manifest as unreachable arms in a match statement (that turn out not to be unreachable) or preemtive assertions to guard against code we don't yet support. To help identify the code that triggers these bugs, there are a few recommended methods for reporting them:
QueryErr::bug: Use this method to report a bug if the code already returns aQueryResult. This approach is preferred because we will correctly recover from the error.span_bug!: When you have aSpanat hand, you can use this macro in place ofpanic!to report the span before panicking.tracked_span_bug!: This macro is similar tospan_bug!, but it uses a span stored in a thread local variable (if one exists). To track a span in the thread local variable you can useflux_common::bug::track_span.bug!: For other cases where none of the above applies, you can use thebug!macro. This behaves mostly likepanic!but with nicer formatting.
When running Flux in a new code base, consider setting the flag FLUX_CATCH_BUGS=1. If this flag is set,
Flux will try to catch and recover from panics emitted with one of the bug macros (using
std::panic::catch_unwind). Bugs are caught at item boundaries. This may leave Flux or rustc
in an inconsistent state, so there are no guarantees that Flux will behave correctly after recovering
from a panic. However, this may still be useful to gather as many errors as possible. Code can
be selectively ignored later.
Dumping the Checker Trace
cargo x install --debug
FLUX_DUMP_CHECKER_TRACE=1 FLUX_CHECK_DEF=mickey cargo flux
python3 path/to/flux/tools/logreader.py
Debugging Extern Specs
To see the expanded code of an extern_spec macro, you can do
cargo x expand path/to/file.rs
(Re)building Libraries
When making changes to the libraries, including flux-core which has the
extern_specifications for the standard library, you can force a rebuild
of the libraries by running:
cargo x build-sysroot
High-level Architecture
Flux is implemented as a compiler driver. We hook into the compiler by implementing the Callbacks trait. The implementation is located is in the flux-driver crate, and it is the main entry point to Flux.
Crates
crates/flux-bin: Contains thecargo-fluxandfluxbinaries used to launch theflux-driver.crates/flux-common: Common utility definitions used across all crates.crates/flux-config: Crate containing logic associated with global configuration flags that change the behavior of Flux, e.g, to enable or disable overflow checking.crates/flux-desugar: Implementation of name resolution and desugaring from Flux surface syntax into Flux high-level intermediate representation (fhir). This includes name resolution.crates/flux-driver: Main entry point to Flux. It contains theflux-driverbinary and the implementation of theCallbackstrait.crates/flux-errors: Utility definitions for user facing error reporting.crates/flux-fhir-analysis: Implements the "analyses" performed in thefhir, most notably well-formedness checking and conversion fromfhirintorty.crates/flux-fixpoint: Code to interact with the Liquid Fixpoint binary.crates/flux-macros: Procedural macros used internally to implement Flux.crates/flux-metadata: Logic for saving Flux crate metadata that can be used to import refined signatures from external crates.crates/flux-middle: This crate contains common type definitions that are used by the rest of Flux like thertyandfhirintermediate representations. Akin torustc_middle.crates/flux-refineck: Implementation of refinement type checking.crates/flux-syntax: Definition of the surface syntax AST and parser.tests: Flux regression tests.lib/flux-attrs: Implementation of user facing procedural macros for annotating programs with Flux specs.lib/flux-rs: This is just a re-export of the macros implemented influx-attrs. The intention is to eventually put Flux "standard library" here, i.e., a set of definitions that are useful when working with Flux.
Intermediate Representations
Flux has several intermediate representations (IR) for types. They represent a refined version of an equivalent type in some rustc IR. We have picked a distinct verb to refer to the process of going between these different representations to make it easier to refer to them. The following image summarizes all the IRs and the process for going between them.

Surface
The surface IR represents source level Flux annotations. It corresponds to the rustc_ast data structures in rustc. The definition as well as the parser is located in the flux-syntax crate.
Fhir
The Flux High-Level Intermediate Representation (fhir) is a refined version of rustc's hir. The definition is located in the flux_middle crate inside the fhir module. The process of going from surface to fhir is called desugaring, and it is implemented in the flux-desugar crate.
Rty
The definition in the flux_middle::rty module correspond to a refined version of the main rustc representation for types defined in rustc_middle::ty. The process of going from fhir to rty is called conversion, and it is implemented in the flux_fhir_analysis::conv module.
Simplified Rustc
The definition in the flux_middle::rustc module correspond to simplified version of data structures in rustc. They can be understood as the currently supported subset of Rust. The process of going from a definition in rustc_middle into flux_middle::rustc is called lowering and it is implemented in flux_middle::rustc::lowering.
Lifting and Refining
Besides the different translation between Flux intermediate representations, there are two ways to get a refined version from a rust type. The process of going from a type in hir into a type in fhir is called lifting, and it is implemented in flux_middle::fhir::lift. The process for going from a type in flux_middle::rustc::ty into a flux_middle::rty is called refining, and it is implemented flux_middle::rty::refining.